
问题情景概述:
① 阿里云服务器 MySQL 经常自动停止、挂掉、重启。
② 阿里云CentOS 7 WordPress 运行时经常数据库连接不上
③ CentOS 7 + Nginx + PHP + MySQL
打开 MySQL 的 error.log 错误信息,在阿里云 Cent OS 的路径为 :
error.log中相关的信息截图如下所示:
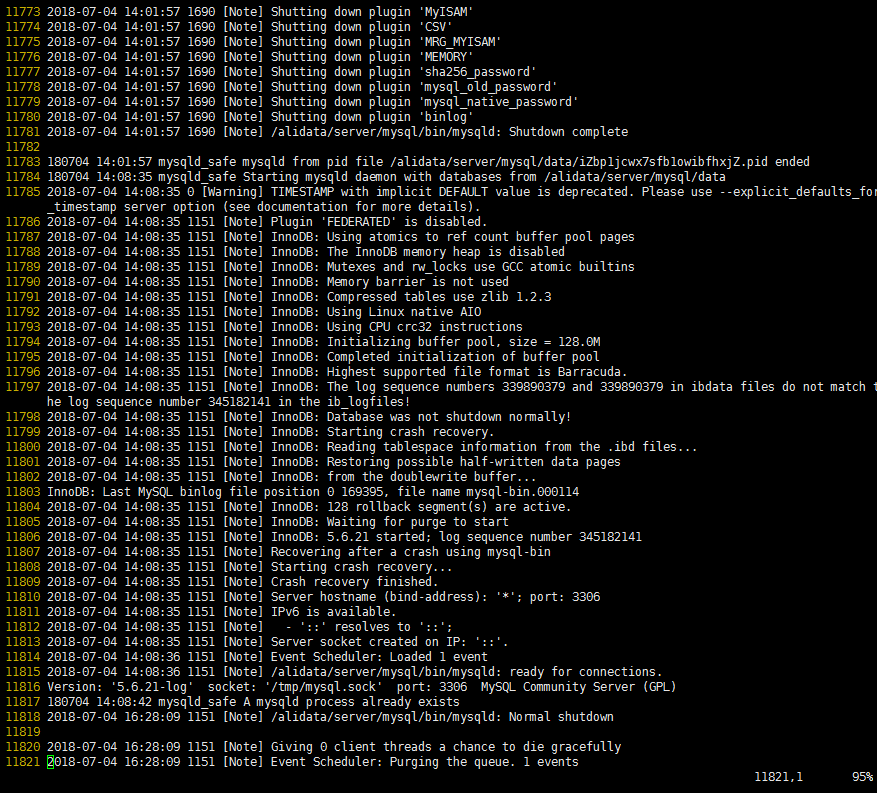
但从 以上 error.log 中很难找出哪里出了问题。去 Google 了一下,给你的方案基本上修改”/alidata/server/mysql/my.cnf”:

innodb_buffer_pool_size = 64M
# 默认为128M,修改成64M、32M或者8M,但实际上重启 MySQL 之后以为能运行,实际上过了一会 MySQL 还是会出现不知原因地自动关闭。
回头再分析error.log,请注意看这一行:
![]()
这句话说明了 MySQL 非正常关闭, MySQL 也不知道自己为什么被关闭掉了。。。囧。于是 MySQL 觉得真奇怪,自己又重启了自己的进程Starting Crash Recovery,如下:
![]()
接着,大家可以发挥想象力猜想下这条日志:
![]()
继续 Google,发现原来是这里在捣鬼,才出现了 MySQL 再重启后,又继续自动关闭,再重启。于是尝试按照 StackOverflow 上面的 suggestions 去做:
Drop your ib_log files and Put innodb_force_recovery=6 in config file and restart your mysql it will resolve
重启又可以了。。。,没一会,嚓,MySQL 又宕机了!这次不仅宕机了,还有副作用,error.log 又多了个因 **innodb_force_recovery = **而引起的错误。
怎么办呢?现在我们还是回到下面这条日志:
![]()
现在我们要看看,为什么 MySQL 会不正常关闭呢?!我们打开top看看,下面使用**top**进行查看(现在已经正常):
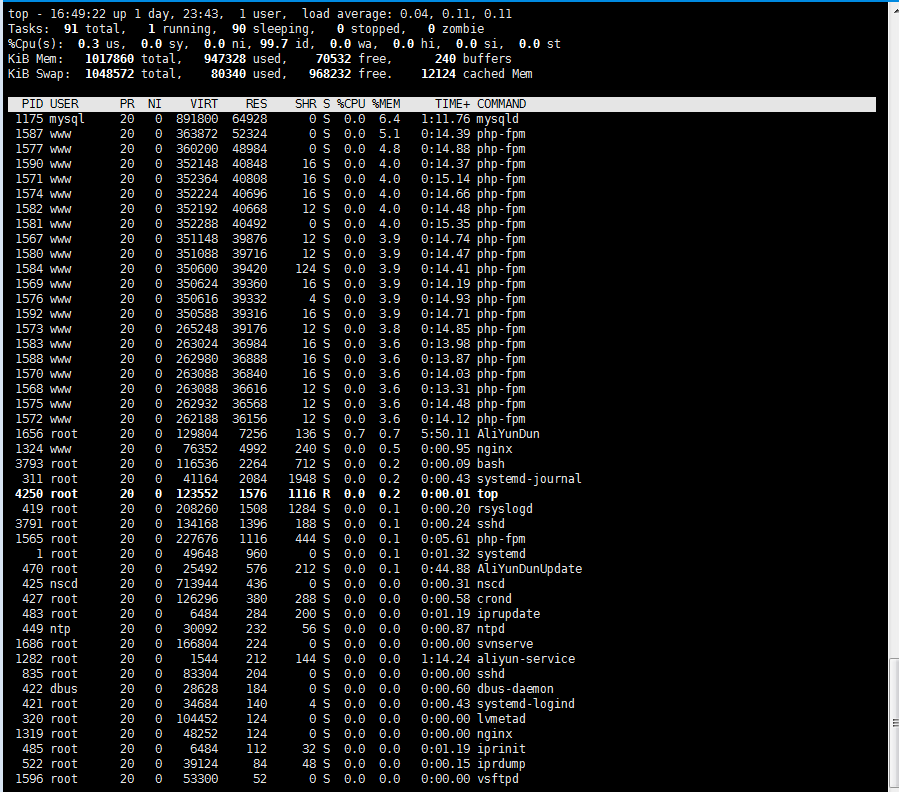
通过 top 命令发现 MySQL 进程占用的 VIRT 居然这么多!这时,你要是多刷新几下服务器上搭建的 WordPress 网站主页,会出现 MySQL 内存占用率超过 50% 的情况,这时 MySQL 进程就会被 Linux 内核杀死。也就出现了我们在 MySQL 的 error.log 中看到的”[Note] InnoDB: Database was not shutdown normally” 日志了。
为了确认这个猜测是否属实,我们去查看下 Kernel 日志,路径及具体信息如下所示:

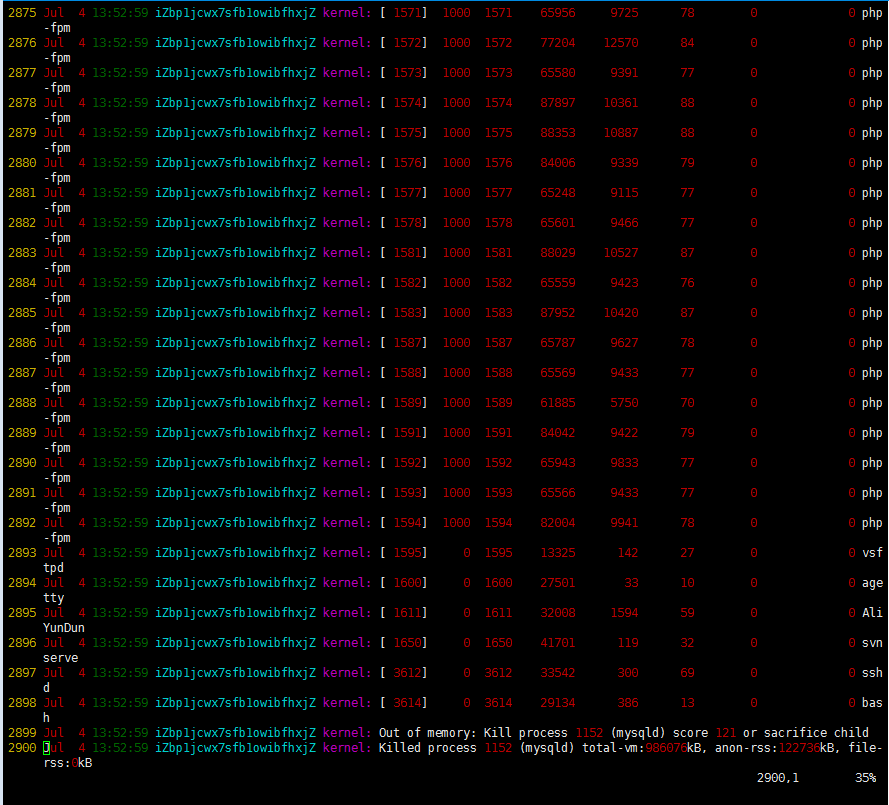
看最后几条内容:

Finally,终于找到原因了,内存不够,杀死了 mysqld 进程。如何解决呢?优化方案如下所示:
⑴ 创建 SWAP 分区:
参考教程:How do you add swap to an EC2 instance?
a. 逐条运行下面的命令:
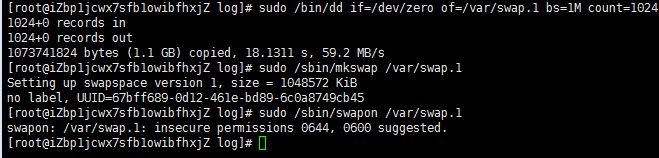
b.将下面一行添加到 /etc/fstab,服务器重启时自动启动 swap:
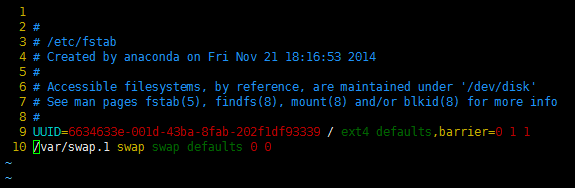
⑵ 降低数据库 InnoDB 引擎的缓冲区大小,以及限制 MySQL 的最大连接数(max_connections):
![]()
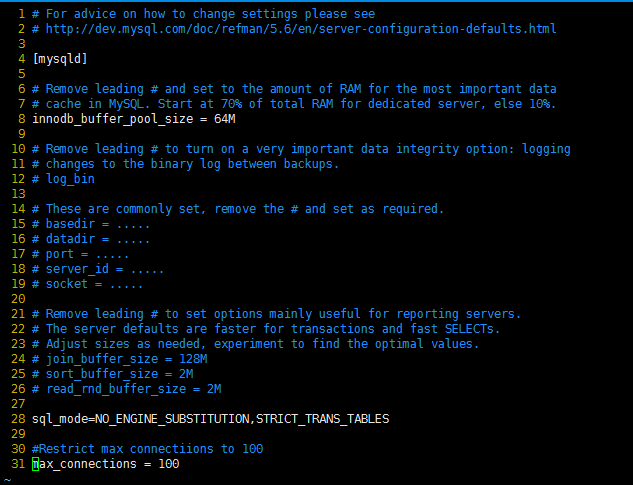
修改完成后重启 MySQL:service mysqld restart
注解:max_connections 的默认值是 151,可以动态更改这个值。参见:max_connections
⑶ nginx 优化:
Optimizing Nginx Configuration
打开”/alidata/server/nginx/conf/nginx.conf”:
![]()
优化配置如下所示:
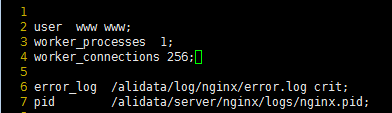
修改完重启 nginx:service nginx restart
如有必要,可以重启服务器:reboot
OK,it’s done!
—EOF—