
最近正在拜读由Ryan Mitchell编写,OReilly出版的Web Scraping with Python。初级爬虫利用urllib、urllib2库以及正则表达式即可完成,不过还有更为强大的工具——Scrapy。虽然文中寥寥数语,不过整个实际安装过程还是煞费苦心呐!!!!
系统:Win7旗舰版,之前安装好的Python 3.6版本,Scrapy安装官网权威参考:点我 ☜☚☜☚
具体安装过程如下所示:
1、Python
选择相应版本的Python,安装过程就不赘述啦,安装成功后记得配置环境变量,比如我的:
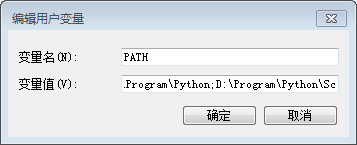
安装及配置好后,在命令行输入python –version,如果没有提示错误,则安装成功。
![]()
2、pywin32
在windows下,必须安装pywin32,安装地址:http://sourceforge.net/projects/pywin32/,下载对应版本的pywin32,直接双击安装即可,安装完成后验证如下,如果没有提示错误,则证明安装成功!

3、pip
pip是用来安装其他必要包的工具,之前已经装好,并且同时,它帮你安装了setuptools,安装完成后在命令行中执行 pip –version,如果提示如下,说明就安装成功了,如果提示不是内部或外部命令,那么就检查一下环境变量有没有配置好,相关路径有两个。
![]()
4、pyOpenSLL
在Linux下是已经安装好的,而在Windows下,是没有预装pyOpenSSL的,安装地址:https://launchpad.net/pyopenssl
5、lxml
lxml的详细介绍点我 ☜☚,是一种使用Python编写的库,可以迅速、灵活地处理XML,直接执行如下命令:
![]()
如果提示Microsoft Visual C++库没有安装,则点我 ☜☚下载支持的库。
安装完成后可以验证下是否成功,如下没有报错则表示成功。
![]() 6、Scrapy
6、Scrapy
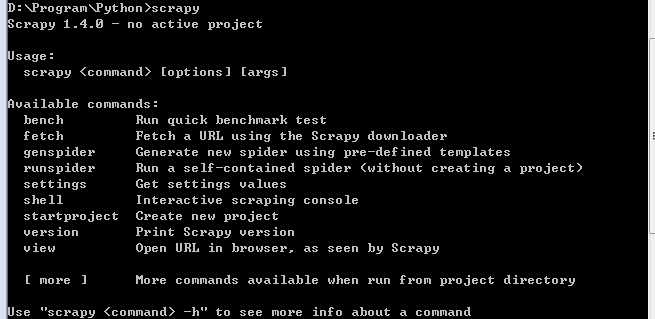
万里长征快要到头啦!!!执行如下命令:

安装完成后输入scrapy进行验证,如果提示如下命令,就证明安装成功啦!
7、其他
有时pip安装并不能成功,需要下载安装文件进行安装,此时需要wheel对相关文件进行安装,安装成功如下:

利用pip成功安装Scrapy之后,import Scrapy的时候报错:
ImportError: DLL load failed: 找不到指定的程序。
原因是因为直接用pip安装Scrapy的时候,安装的是3.8.0版本的lxml。将lxml的版本改为3.7.3即可。
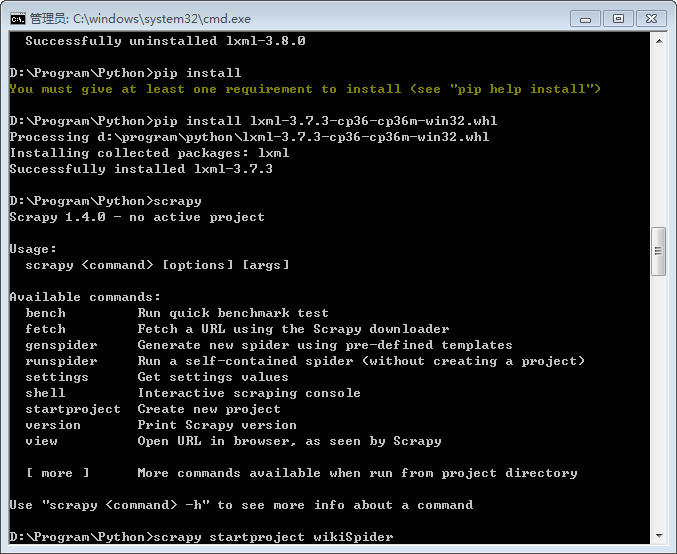

scrapy安装成功并验证后,创建首个项目叫wikiSpider,项目目录如下:

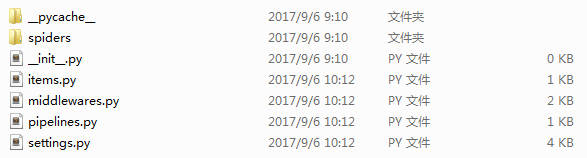
至此可以根据自身需求开始愉快的玩耍啦!哒哒!!