
The SQL operations union, intersect, and except operate on relations and correspond to the mathematical set-theory operations ∪, ∩, —. We shall now construct queries involving the union, intersect, and except operations over two sets.
1、Set Operations
- The set of all courses taught in the Fall 2009 semester:

- The set of all courses taught in the Spring 2010 semester:

1.1 The Union Operation
To find the set of all courses taught either in Fall 2009 or in Spring 2010, or both, we write: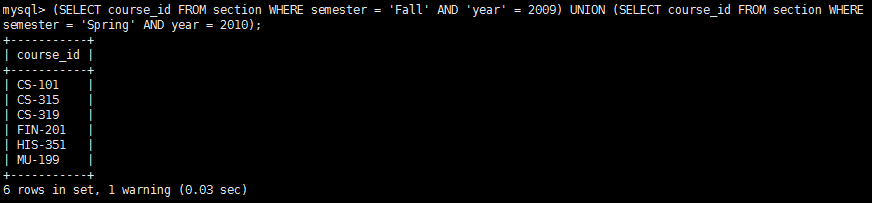 The union operation automatically eliminates duplicates, unlike the select clause. If we want to retain all duplicates, we must write union all in place of union:
The union operation automatically eliminates duplicates, unlike the select clause. If we want to retain all duplicates, we must write union all in place of union: The number of duplicate tuples in the result is equal to the total number of duplicates that appear in both c1 and c2. So, in the above query, each of CS-319 and CS-101 would be listed twice.
The number of duplicate tuples in the result is equal to the total number of duplicates that appear in both c1 and c2. So, in the above query, each of CS-319 and CS-101 would be listed twice.
1.2 The Intersect Operation (Inner Join for MySQL)
To find all items in the instructor relation and teaches relation using an ID we write:

 1.3 The Except Operation
1.3 The Except Operation
To find all instructor.ID in the instructor relation but not in the teaches relation, we write:
2、Null Values
Null values present special problems in relational operations, including arithmetic operations, comparison operations and set operations.
The result of an arithmetic expression ( involving, for example +, -, *, or / ) is null if any of the input values is null. For example, if a query has an expression r.A + 5, and r.A is null for a particular tuple, then the expression result must also be null for that tuple.
Comparisons involving nulls are more of a problem. For example, consider the comparison “1 < null“. It would be wrong to say this is true since we do not know what the null value represents. But it would likewise be wrong to claim this expression is false; if we did, “not (1 < null)” would evaluate to true, which does not make sense. SQL therefore treats as unknown the result of any comparison involving a null value (other than predicates is null and is not null, which are described later). This creates a third logical value in addition to true and false.
Since the predicate in a where clause can involve Boolean operations such as and, or, and not on the results of comparisons, the definitions of the Boolean operations are extended to deal with the value unknown.
- and: The result of true and unknown is unknown, false and unknown is false, while unknown and unknown is unknown.
- or: The result of true or unknown is true, false or unknown is unknown, while unknown or unknown is unknown.
- not: The result of not unknown is unknown.
You can verify that if r.A is null, then “1 < r.A” as well as “not ( 1 < r.A )” evaluate to unknown. If the where clause predicate evaluates to either false or unknown for a tuple, that tuple is not added to the result. SQL uses the special keyword null in a predicate to test for a null value. Thus, to find all instructors who appear in the instructor relation with null values for salary, we write: The predicate is not null succeeds if the value on which it is applied is not null.
The predicate is not null succeeds if the value on which it is applied is not null.
Some implementations of SQL also allow us to test whether the result of a comparison is unknown, rather than true of false, by using the clauses is unknown and is not unknown.
When a query uses the select distinct clause, duplicate tuples must be eliminated. For this purpose, when comparing values of corresponding attributes from two tuples, the values are treated as identical if either both are non-null and equal in value, or both are null. Thus two copies of a tuple, such as {(‘A’,null),(‘A’,null)}, are treated as being identical, even if some of the attributes have a null value. Using the distinct clause then retains only one copy of such identical tuples. Note that the treatment of null above is different from the way nulls are treated in predicates, where a comparison “null=null” would return unknown, rather than true.
The above approach of treating tuples as identical if they have the same values for all attributes, even if some of the values are null, is also used for the set operations union, intersection and except.
3、Aggregate Functions
Aggregate functions are functions that take a collection (a set or multiset) of values as input and return a single value. SQL offers five built-in aggregate functions:
- Average: avg
- Minimum: min
- Maximum: max
- Total: sum
- Count: count
The input to sum and avg must be a collection of numbers, but the other operators can operate on collections of nonnumeric data types, such as strings, as well.
3.1 Basic Aggregation
Consider the query “Find the average salary of instructors in the Computer Science department.” We write this query as follows:
The results of this query is a relation with a single attribute, containing a single tuple with a numerical value corresponding to the average salary of instructors in the Computer Science department. The database system may give an arbitrary name to the result relation attribute that is generated by aggregation; however, we can give a meaningful name to the attribute by using the as clause as follows: The salaries in the Computer Science department are $75000, $65000, and $92000. The average balance is $232000/3 = $77333.33. Retaining duplicates is important in computing an average. Suppose the Computer Science department adds a fourth instructor whose salary happens to be $75000. If duplicates were eliminated, we would obtain the wrong answer( $232000/4 = $58000 ) rather than the correct answer of $76750.
The salaries in the Computer Science department are $75000, $65000, and $92000. The average balance is $232000/3 = $77333.33. Retaining duplicates is important in computing an average. Suppose the Computer Science department adds a fourth instructor whose salary happens to be $75000. If duplicates were eliminated, we would obtain the wrong answer( $232000/4 = $58000 ) rather than the correct answer of $76750.
There are cases where we must eliminate duplicates before computing an aggregate function. If we do want to eliminate duplicates, we use the keyword distinct in the aggregate expression. An example arises in the query “Find the total number of instructors who teach a course in the Spring 2010 semester.” In this case, an instructor counts only once, regardless of the number of course sections that the instructor teaches. The required information is contained in the relation teaches, and we write this query as follows: Because of the keyword distinct preceding ID, even if an instructor teaches more than one course, she is counted only once in the result.
Because of the keyword distinct preceding ID, even if an instructor teaches more than one course, she is counted only once in the result.
We use the aggregate function count frequently to count the number of tuples in a relation. The notation for this function in SQL is count( * ). Thus, to find the number of tuples in the course relation, we write: SQL does not allow the use of distinct with count( * ). It is legal to use distinct with max and min, even though the result does not change. We can use the keyword all in place of distinct to specify duplicate retention, but, since all is the default, there is no need to do so.
SQL does not allow the use of distinct with count( * ). It is legal to use distinct with max and min, even though the result does not change. We can use the keyword all in place of distinct to specify duplicate retention, but, since all is the default, there is no need to do so.
3.2 Aggregation with Grouping
There are circumstances where we would like to apply the aggregate function not only to a single set of tuples, but also to a group of sets to tuples; we specify this wish in SQL using the group by clause. The attribute or attributes given in the group by clause are used to form groups. Tuples with the same value on all attributes in the group by clause are placed in one group.
As an illustration, consider the query “Find the average salary in each department.” We write this query as follows:
select dept_name, avg(salary) as avg_salary from instructor group by dept_name;
 Figure above shows the tuples in the instructor relation grouped by the dept_name attribute, which is the first step in computing the query result. The specified aggregate is computed for each group, and the result of the query is shown below.
Figure above shows the tuples in the instructor relation grouped by the dept_name attribute, which is the first step in computing the query result. The specified aggregate is computed for each group, and the result of the query is shown below. In contrast, consider the query “Find the average salary of all instructors.” We write this query as follows:
In contrast, consider the query “Find the average salary of all instructors.” We write this query as follows: In this case the group by clause has been omitted, so the entire relation is treated as a single group.
In this case the group by clause has been omitted, so the entire relation is treated as a single group.
As another example of aggregation on groups of tuples, consider the query “Find the number of instructors in each department who teach a course in the Spring 2010 semester.” Information about which instructors teach which course sections in which semester is available in the teaches relation. However, this information has to be joined with information from the instructor relation to get the department name of each instructor. Thus, we write this query as follows: The result is shown above.
The result is shown above.
When an SQL query uses grouping, it is important to ensure that the only attributes that appear in the select statement without being aggregated are those that present in the group by clause. In other words, any attribute that is not present in the group by clause must appear only inside an aggregate function if it appears in the select clause, otherwise the query is treated as erroneous. For example, the following query is erroneous since ID not appear in the group by clause, and yet it appears in the select clause without being aggregated: Each instructor in a particular group ( defined by dept_name ) can have a different ID, and since only one tuple is output for each group, there is no unique way of choosing which ID value to output, As a result, such cases are disallowed by SQL.
Each instructor in a particular group ( defined by dept_name ) can have a different ID, and since only one tuple is output for each group, there is no unique way of choosing which ID value to output, As a result, such cases are disallowed by SQL.
3.3 The Having Clause
At times, it is useful to state a condition that applies to groups rather than to tuples. For example, we might be interested in only those departments where the average salary of the instructors is more than $42000. This condition does not apply to a single tuple; rather, it applies to each group constructed by the group by clause. To express such a query, we use the having clause of SQL. SQL applies predicates in the having clause after groups have been formed, so aggregate functions may be used. We express this query in SQL as follows: As was the case for the select clause, any attribute that is present in the having clause without being aggregated must appear in the group by clause, otherwise the query is treated as erroneous. The meaning of a query containing aggregation, group by, or having clauses is defined by the following sequence of operations:
As was the case for the select clause, any attribute that is present in the having clause without being aggregated must appear in the group by clause, otherwise the query is treated as erroneous. The meaning of a query containing aggregation, group by, or having clauses is defined by the following sequence of operations:
⑴ As was the case for queries without aggregation, the from clause is first evaluated to get a relation.
⑵ If a where clause is present, the predicate in the where clause is applied on the result relation of the from clause.
⑶ Tuples satisfying the where predicate are then placed into groups by the group by clause if it is present. If the group by clause is absent, the entire set of tuples satisfying the where predicate is treated as being in one group.
⑷ The having clause, if it is present, is applied to each group; the groups that do not satisfy the having clause predicate are removed.
⑸ The select clause uses the remaining groups to generate tuples of the result of the query, applying the aggregate functions to get a single result tuple for each group.
3.4 Aggregation with Null and Boolean Values
Null values, when they exist, complicate the processing of aggregate operators. For example, assume that some tuples in the instructor relation have a null value for salary. Consider the following query to total all salary amounts: The values to be summed in the preceding query include null values, since some tuples have a null value for salary. Rather than say that the overall sum is itself null, the SQL standard says that the sum operator should ignore null values in its input.
The values to be summed in the preceding query include null values, since some tuples have a null value for salary. Rather than say that the overall sum is itself null, the SQL standard says that the sum operator should ignore null values in its input.
In general, aggregate functions treat nulls according to the following rule: All aggregate functions except count( * ) ignore null values in their input collection. As a result of null values being ignored, the collection of values may be empty. The count of an empty collection is defined to be 0, and all other aggregate operations return a value of null when applied on an empty collection. The effect of null values on some of the more complicated SQL constructs can be subtle.
A Boolean data type that can take values true, false, and unknown, was introduced in SQL:1999. The aggregate functions some and every, which mean exactly what you would intuitively expect, can be applied on a collection of Boolean values.