
Docker的兴起和发展与我的工作轨迹一直是平行的,直到在 酷壳 中读到相关技术文章,才勾起对Linux的一些记忆、一些联想。对模糊、朦胧、未知的东西,心里总会产生强烈好奇心,决定好好探究一番。哲学终极三问上线:你是谁?你从哪里来?你要到哪里去?本文不会对Docker未来产生任何影响,当然也就不做任何评价。
Docker – Build, Ship, and Run Any App, Anywhere !
什么是Docker呢?Docker是一个开源的引擎,可以轻松的为任何应用创建一个轻量级的、可移植的、自给自足的容器。开发者在笔记本上编译测试通过的容器可以批量地在生产环境中部署,包括VMs(虚拟机)、bare metal、Openstack 集群和其他的基础应用平台。
Docker由以下部分组成:
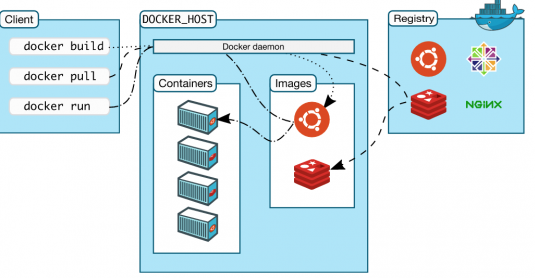
- Docker Client:Docker提供给用户的客户端。用户输入Docker提供的命令来管理本地或者远程的服务器。
- Docker Daemon:Docker服务的守护进程。每台服务器(物理机或虚拟机)上只要安装了Docker的环境,基本上就跑了一个后台程序 Docker Daemon,Docker Daemon会接收Docker Client发过来的指令,并对服务器进行具体操作。
- Docker Images:俗称Docker的镜像。简单理解为系统CD盘,里面有操作系统程序,并且还有一些CD盘在系统基础上安装了必要的软件,做成了一张“只读”CD。
- Docker Registry:可认为是Docker Images的仓库,就像git仓库一样,用来管理Docker镜像的,提供了Docker镜像的上传、下载和浏览等功能,并且提供安全的账号管理可以管理只有自己可见的私人Image。像git的仓库一样,Docker也提供了官方的Registry,叫做Dock Hub。
- Docker Container:俗称Docker的容器,这最为关键。Docker Container是真正跑项目程序、消耗机器资源、提供服务的地方,Docker Container通过Docker Images启动,在Docker Images的基础上运行你需要的代码。即Docker Container提供了系统硬件环境,然后使用了Docker Images这些制作好的系统盘,再加上你的项目代码,跑起来就可以提供服务了。听起来可能和VIM利用保存的备份或者快照跑起来环境一样,但是两者存在本质区别。
Docker应用场景包括:
- web应用的自动化打包和发布;
- 自动化测试和持续集成、发布;
- 在服务型环境中部署和调整数据库或其他的后台应用;
- 从头编译或者扩展现有的 OpenShift 或 Cloud Foundry 平台来搭建自己的PaaS环境。
看完瞬间感觉好高端的样子,难免心里嘀咕是不是个坑呀?不过读完 酷壳 中相关技术文章着实让人有了继续研究的欲望,入坑又何妨!!!
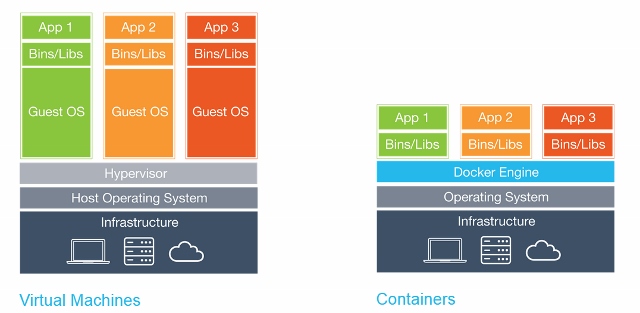
我们知道VM技术可以将一台物理机器部署为多台虚拟机器,解决了很多物力资源的浪费以及方便的管理能力。其中的关键在于VM在物理机器的操作系统上建立了一个中间软件层Hypervisor,Hypervisor利用物理机器的资源,虚拟出多个新虚拟的硬件环境,这些硬件环境可以共享宿主机的资源。这些新的虚拟的硬件环境,安装操作系统和相应的软件后便形成了一台台的虚拟机器。
那么Docker有什么特别之处呢?Docker很聪明的利用Linux的一些技术走了一条捷径:Docker选择了和虚拟化完全不同的思路,并不去虚拟化任何硬件,而是对硬件资源在不同的Docker Container之间做了“隔离”。隔离使每个Docker Container之间拥有了不同的环境(硬盘空间、网络、系统的工具包),并且又可以共享需要的硬件资源(CPU、内存、系统内核),达到了和虚拟机能提供的同样的功能。这样做的好处体现在:Docker Image的体积非常小;Docker的系统启动的耗时为0;Docker系统占用资源极少。
Docker使用的Linux核心的组件如下:☛☛☛☛Docker原理图解及全环境安装
- AUFS(chroot) — 用来建立不同的操作系统和隔离运行时的硬盘空间
- Namespace — 用来隔离Container的执行空间
- Cgroup — 分配不用的硬件资源
- SELinux — 用来保护Linux的网络安全
- Netlink — 用来让不同的Container之间的进程保持通信
- Netfilter — 建立Container埠为基础的网络防火墙封包过滤
- AppArmor — 保护Container的网络及执行安全
- Linux Bridge — 让不同Container或不同主机上的Container能沟通
- 。。。
以上每一项技术都值得深入研究,本文主要对Namespace进行相关阐述。
简介
Linux Namespace是Linux提供的一种内核级别环境隔离的方法。很早之前Unix有一个叫chroot的系统调用(通过修改根目录把用户jail到一个特定目录下),chroot提供了一种简单的隔离模式:chroot内部的文件系统无法访问外部的内容。Linux Namespace在此基础上,提供了对UTS、IPC、mount、PID、network、User等的隔离机制。
我们都知道Linux下的超级父亲进程的PID是 1,所以同chroot一样,如果我们可以把用户的进程空间jail到某个进程分支下,并像chroot那样让其下面的进程看到的那个超级父进程的PID为1,于是就可以达到资源隔离的效果了(不同的PID namespace中的进程无法看到彼此)
Linux Namespace有如下种类,☞☞☟☟
Mount namespaces — CLONE_NEWNS — Linux 2.4.19
UTS namespaces — CLONE_NEWUTS — Linux 2.6.19
IPC namespaces — CLONE_NEWIPC — Linux 2.6.19
PID namespaces — CLONE_NEWPID — Linux 2.6.24
Network namespaces — CLONE_NEWNET — 始于Linux 2.6.24 完成于 Linux 2.6.29
User namespaces — CLONE_NEWUSER — 始于Linux 2.6.23 完成于 Linux 3.8
主要是三个系统调用
- clone()——实现线程的系统调用,用来创建一个新的进程,并可以通过设计上述参数达到隔离
- unshare()——使某进程脱离某个namespace
- setns()——把某进程加入到某个namespace
unshare()和setns()都相对比较简单,可自行man。主要对clone()进行阐述。
clone()系统调用
首先,以下为一个最简单的clone()系统调用示例:
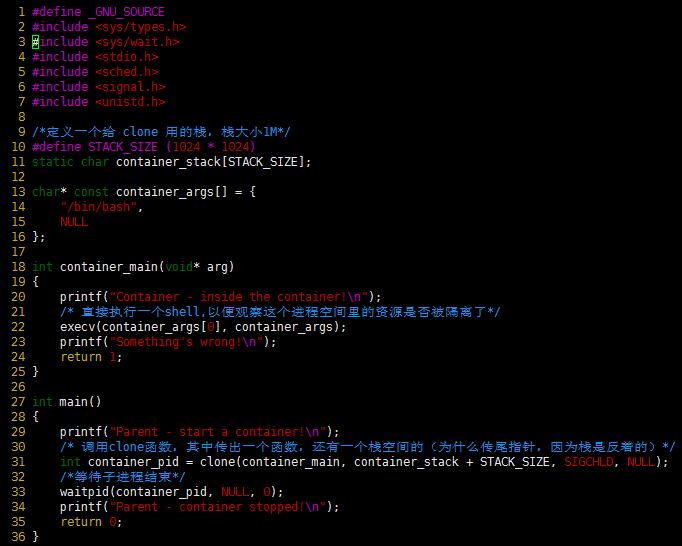
从上面的程序可以看到,这和pthread基本上是一样的玩法。但是,对于上面的程序,父子进程的进程空间是没有什么差别的,父进程能访问到的子进程也能。
下面我们来看看,Linux的Namespace是什么样的。
UTS Namespace
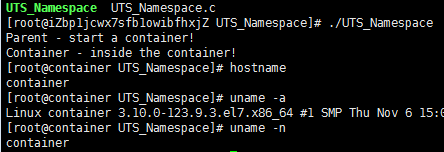
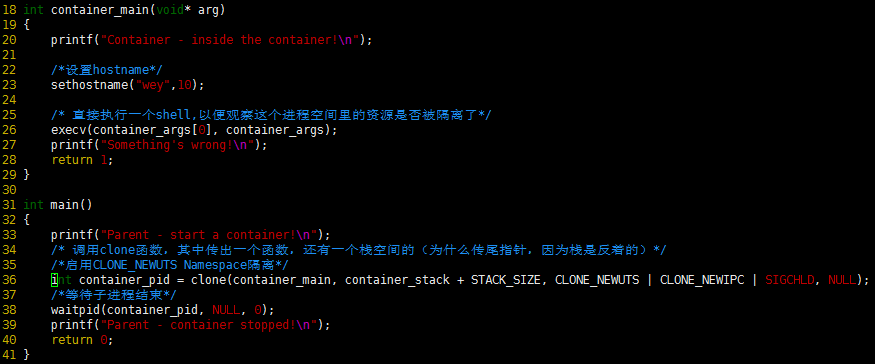
下面的代码是在上面代码的基础上改的,略去了些头文件和数据结构的定义,只有最重要的部分。
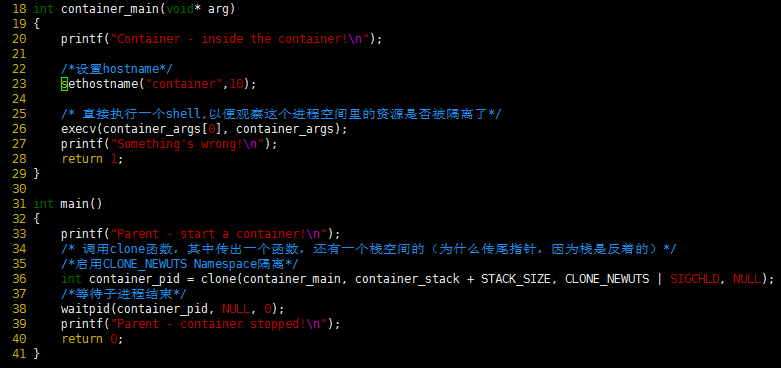
运行上面的程序你会发现(需要root权限),子进程的hostname变成了container
IPC Namespace
IPC全称 Inter-Process Communication,是Unix/Linux下进程间通信的一种方式,IPC有共享内存、信号量、消息队列等方法。故为了隔离,我们也需要把IPC给隔离开来,这样,只有在同一个Namespace下的进程才能相互通信。如果你熟悉IPC的原理的话,会知道IPC需要有一个全局的ID,既然是全局的,那么就意味着我们的Namespace需要对这个ID隔离,不能让别的Namespace的进程看到。
要启动IPC隔离,我们只需要在调用clone时加上CLONE_NEWIPC参数即可。
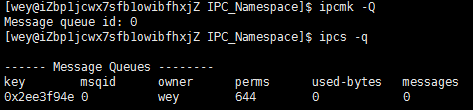
首先,我们先创建一个IPC的Queue(如下所示,全局的Queue ID是0)
如果我们运行没有CLONE_NEWIPC的程序,我们会看到,在子进程中还是能看到这个全启的IPC Queue。
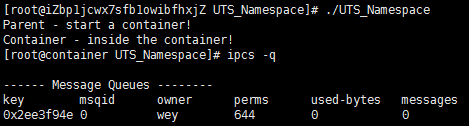
但是,如果我们运行加上了CLONE_NEWIPC的程序,我们就会下面的结果:
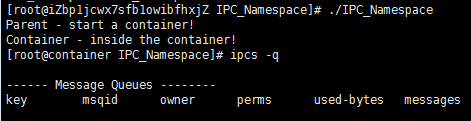
我们可以看到IPC已经被隔离了。
PID Namespace
我们继续修改上面的程序:
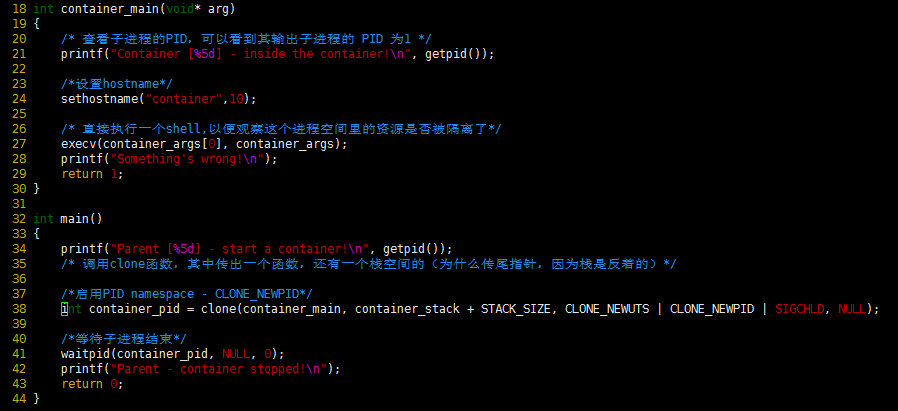
运行结果如下(我们可以看到,子进程的pid是1了)

此处可能会有疑问?PID为1有什么用呢?我们知道,在传统的Unix系统中,PID为1的进程是init,地位非常特殊。他作为所有进程的父进程,有很多特权(比如:屏蔽信号等),另外,其还会检查所有进程的状态,如果某个子进程脱离了父进程(父进程没有wait它),那么init就会负责回收资源并结束这个子进程。所以,要做到进程空间的隔离,首先要创建出PID为1的进程,最好就像chroot那样,把子进程的PID在容器内变成1。
但是,我们会发现,在子进程的shell里输入ps,top等命令,我们还是可以看得到所有进程。说明并没有完全隔离。这是因为,像ps,top这些命令会去读/proc文件系统,所以,因为/proc文件系统在父进程和子进程都是一样的,所以这些命令显示的东西都是一样的。所以,我们还需要对文件系统进行隔离。
Mount Namespace
下面的例程中,我们在启用了mount namespace并在子进程中重新mount了/proc文件系统。
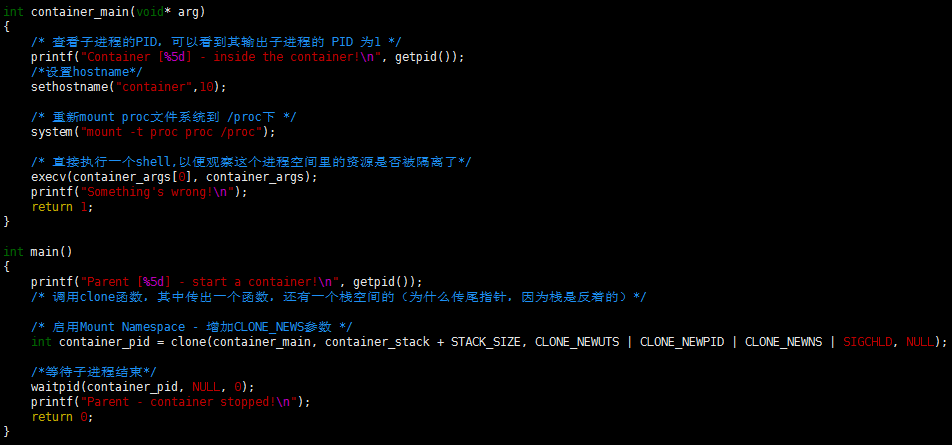
运行结果如下:


上面,我们可以看到只有两个进程,而且pid = 1的进程是我们的/bin/bash。我们还可以看到/proc目录下也干净了很多:
下图,我们也可以看到在子进程中的top命令只看得到两个进程了。
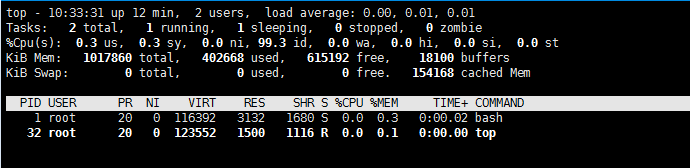
这里,多说一下,在通过CLONE_NEWNS创建mount namespace后,父进程会把自己的文件结构复制给子进程中。而子进程中新的namespace中的所有mount操作都只影响自身的文件系统,而不对外界产生任何影响。这样可以做到比较严格地隔离。
你可能会问,我们是不是还有别的一些文件系统也需要这样mount?是的。
Docker 的 Mount Namespace
下面将演示一个“山寨镜像”,其模仿了Docker的Mount Namespace。
首先,我们需要一个rootfs,即需要把我们要做的镜像中的那些命令什么的copy到一个rootfs的目录下,我们模仿Linux构建如下的目录:
![]()
然后,我们把一些我们需要的命令copy到rootfs/bin目录中(sh命令必须copy进去,不然我们无法chroot)
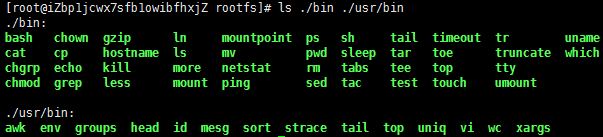
注:你可以使用ldd命令把这些命令相关的那些so文件copy到对应的目录:

下面是rootfs中的一些so文件:
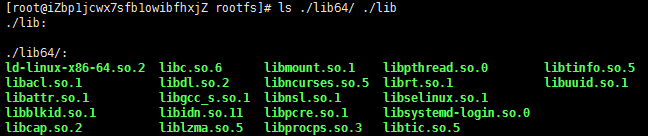
包括这些命令依赖的一些配置文件:
![]()
这时你会说,我靠,有些配置我希望是在容器启动发动时给他设置的,而不是hard code在镜像中的。比如:/etc/hosts,/etc/hostname,还有DNS的/etc/resolv.conf文件。好的,那就在rootfs外面,再创建一个conf目录,把这些文件放到这个目录中。
![]()
这样,我们的父进程就可以动态的设置容器需要的这些文件的配置。然后再把他们mount进容器,这样,容器的镜像中的配置就比较灵活了。
关于如何做一个chroot的目录,这里有个工具叫DebootstrapChroot,可以顺着链接去看看。