
CPU~Central Processing Unit 代表中央处理器,GPU~Graphics Processing Unit 代表图形处理器,在进行具体对比分析前,要明白两者之间仍具有共性:都有总线和外界联系,具有自身的缓存体系,以及数字和逻辑运算单元,简而言之,两者都为了完成计算任务而设计。
一款芯片的速度主要取决于三个方面:微架构、主频、IPC~每个时钟周期执行的指令数
1、微架构
先直观地上个示意图:
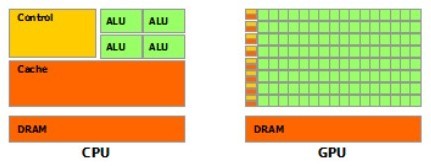
尽管两者都是为了计算任务而设计,但具体设计目标却不尽相同,分别针对两种不同的场景。CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理,故CPU的内部结构异常复杂。而GPU面对的则是类型高度统一的,相互无依赖的大规模数据和不需要被打断的纯净的计算环境。于是CPU和GPU就呈现出非常不同的微架构,如上图所示,图片源于nVidia CUDA文档。其中绿色的是计算单元,橙红色的是存储单元,橙黄色的是控制单元。
GPU采用了数量众多的计算单元和超长的流水线,但只有非常简单的控制逻辑并省去了Cache;而CPU不仅被Cache占据了大量空间,而且还有复杂的控制逻辑和诸多优化电路,相比之下计算能力只是CPU很小的一部分。
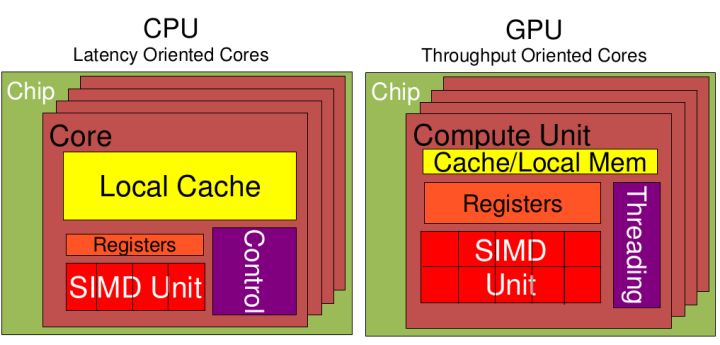
从上图中可以看出:
Cache,local memory:CPU > GPU
Threads(线程数):GPU > CPU
Registers:GPU > CPU 多寄存器可以支持非常多的Thread,thread需要用到register,thread数目大,register也必须跟着很大才行。
SIMD Unit~单指令多数据流,以同步方式,在同一时间内执行同一条命令:
GPU > CPU.
1.1 CPU基于低延时设计
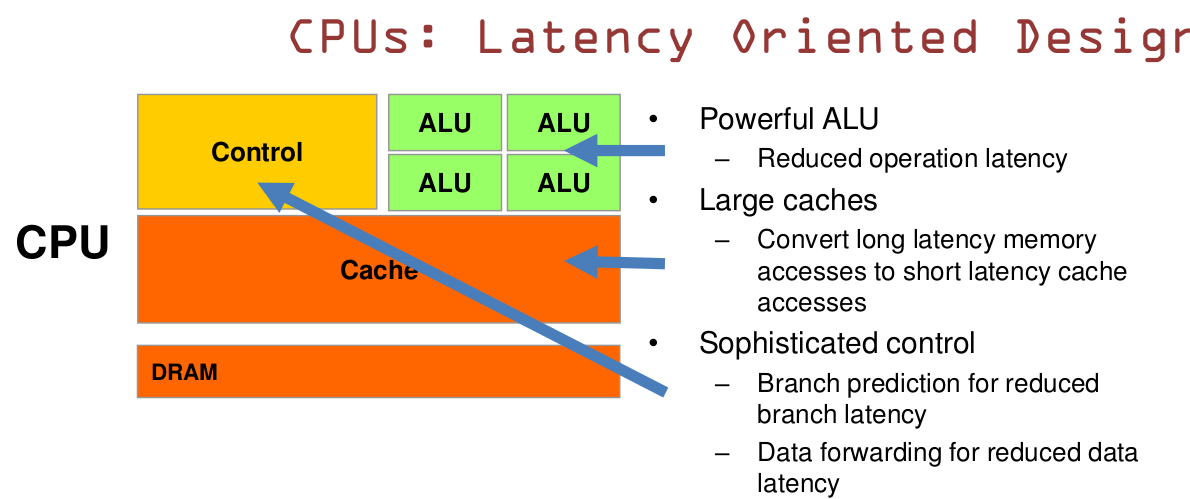
CPU拥有强大的ALU~算术运算单元,它可以在很少的时钟周期内完成算术计算。当今的CPU可以达到64bit双精度,执行双精度浮点运算的加法和乘法只需要1~3个周期。CPU的频率是非常高的,达到1.532~4gigahertz(千兆Hz)
大的缓存同样可以降低延时,保存众多的数据放在缓存里面,当需要访问这些数据时,只要是之前访问过的,如今直接在缓存里面取即可。
复杂的逻辑控制单元,当程序含有多个分支的时候,它通过提供分支预测的能力来降低延时。
数据转发,当一些指令依赖前面的指令结果时,数据转发的逻辑控制单元决定这些指令在pipline中的位置并且尽可能快的转发一个指令的结果给后续的指令,这些动作需要很多的对比电路单元和转发电路单元。
1.2 GPU基于大吞吐量设计
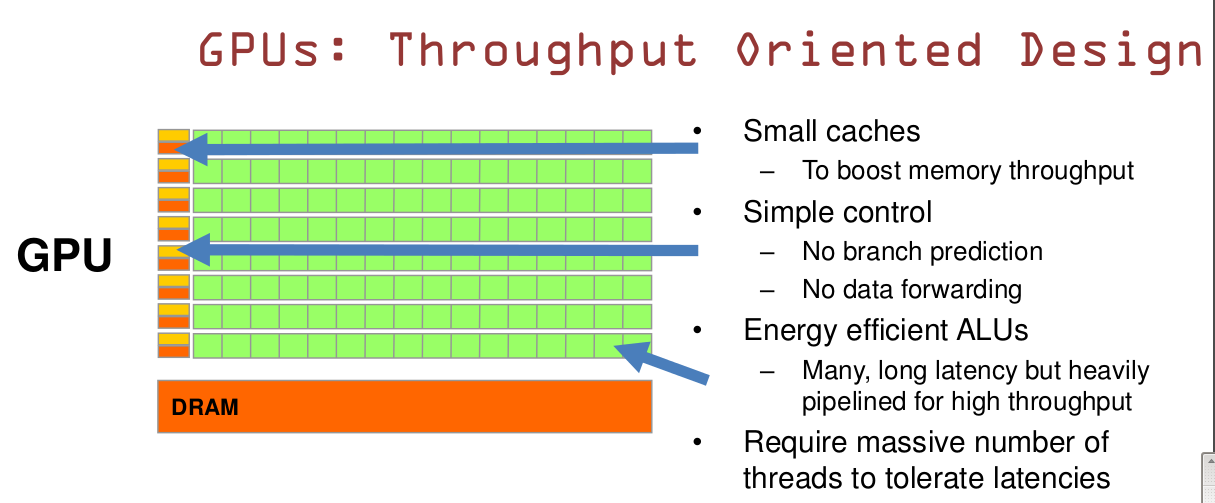
GPU的特点是有很多的ALU和很少的Cache。缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,该处缓存的目的是为thread提高服务的。如果有很多线程需要访问一个相同的数据,缓存会合并这些访问,然后再去访问DRAM(因为需要访问的数据保存在DRAM中,而不是在Cache里面),获取数据后Cache会转发这个数据给对应的线程,此时是数据转发的角色。但是由于需要访问DRAM,自然会带来延时的问题。
GPU的控制单元(左边黄色区域块)可以把多个访问合并成少的访问。
GPU虽然有DRAM延时,却有非常多的ALU和非常多的thread。为了平衡内存延时的问题,我们可以充分利用ALU多的特性达到一个非常大的吞吐量的效果。尽可能多的分配多的threads。通常来看GPU ALU会有非常重的pipeline就是鉴于此。
故与CPU擅长逻辑控制、串行计算、通用类型数据运算不同,GPU擅长的是大规模并发计算,也正是密码破解等所需要的,所以GPU除了图像处理,也越来越多的参与与到计算中来。
什么类型的程序适合在GPU上运行?
⑴ 计算密集型的程序:所谓计算密集型~Compute-intensive的程序,即其大部分运行时间花在了寄存器运算上,寄存器的速度和处理器的速度相当,从寄存器读写数据几乎没有延时。可以对比下,读内存的延迟大概是几百个时钟周期;读硬盘的速度,即使是SSD,也实在是太慢了。
⑵ 易于并行的程序:GPU其实是一种SIMD~Single Instruction Multiple Data架构,它有成百上千个核,每个核在同一时间最好能做同样的事情。
2、主频
除了微架构,在主频上两者区别也比较明显,GPU执行每个数值计算的速度并没有比CPU块,从目前主流CPU和GPU的主频可以看出,CPU的主频都超过了1GHz,2GHz,甚至3GHz,而GPU的主频最高还不到1GHz,主流的也就500~600MHz。故GPU在执行少量线程的数值计算时并不能超过CPU。
目前GPU数据计算的优势主要在于浮点运算,它执行浮点运算快是靠大量并行,但是这种数值计算的并行性在面对程序的逻辑执行时毫无用处。
3、IPC~每个时钟周期执行的指令数
这个方面,CPU和GPU无法比较,因为GPU大多数指令都是面向数据计算的,少量的控制指令也无法被操作系统和软件直接使用。如果比较数据指令的IPC,GPU显然要高过CPU,原因在于并行计算。但是如果比较控制指令的IPC,自然是CPU的要高的多。原因很简单,CPU着重的是指令执行的并行性。另外,目前有些GPU也能够支持比较复杂的控制指令,比如条件转移、分支、循环和子程序调用等,但是GPU程序控制这方面的增加,和支持操作系统所需要的能力CPU相比还是有天壤之别,而且指令执行的效率也无法和CPU相提并论。
4、本文小结
CPU擅长:操作系统,系统软件,应用程序,通用计算,系统控制等等;游戏中人工智能,物理模拟等等;3D建模-光线追踪渲染;虚拟化技术——抽象硬件,同时运行多个操作系统或者一个操作系统的多个副本等等。
GPU擅长:图形类矩阵运算,非图形类并行数值计算,高端3D游戏。
5、延伸阅读