
In previous series, we covered a number of built-in data types supported in SQL, such as integer types, real types, and character types. There are additional built-in data types supported by SQL, which we describe below. We also describe how to create basic user-defined types in SQL.1、SQL Data Types and Schemas
1.1 Date and Time Types in SQL
In addition to the basic data types we introduced in previous section, the SQL standard supports several data types relating to dates and times:
- date: A calendar date containing a (four-digit) year, month, and day of the month.
- time: The time of day, in hours, minutes, and seconds. A variant, time(p), can be used to specify the number of fractional digits for seconds (the default begin 0). It is also possible to store time-zone information along with the time by specifying time with timezone.
- timestamp: A combination of date and time. A variant, timestamp(p), can be used to specify the number of fractional digits for seconds (the default here being 6). Time-zone information is also stored if with timezone is specified.
Date and time values can be specified like this: Dates must be specified in the format year followed by month followed by day, as shown. The seconds field of time or timestamp can have a fractional part, as in the timestamp above. We can use an expression of the form cast e as t to convert a character string (or string valued expression) e to the type t, where t is one of date, time, or timestamp. The string must be in the appropriate format as illustrated at the beginning of this approach. When required, time-zone information is inferred from the system setting.
Dates must be specified in the format year followed by month followed by day, as shown. The seconds field of time or timestamp can have a fractional part, as in the timestamp above. We can use an expression of the form cast e as t to convert a character string (or string valued expression) e to the type t, where t is one of date, time, or timestamp. The string must be in the appropriate format as illustrated at the beginning of this approach. When required, time-zone information is inferred from the system setting.
To extract individual fields of a date or time value d, we can use extract (field from d), where field can be one of year, month, day, hour, minute, or second. Time-zone information can be extracted using timezone_hour and timezone_minute. SQL defines several functions to get the current date and time. For example, current_date returns the current date, current_time returns the current time (with time zone), and localtime returns the current local time (without time zone). Timestamps (date plus time) are returned by current_timestamp (with time zone) and localtimestamp (local date and time without time zone).
SQL allows comparison operations on all the types listed here, and it allows both arithmetic and comparison operations on the various numeric types. SQL also provides a data type called interval, and it allows computations based on dates and times and on intervals. For example, if x and y are of type date, then x – y is an internal whose value is the number of days from date x to date y. Similarly, adding or subtracting an interval to a date or time gives back a date or time, respectively.
1.2 Default Values
SQL allows a default value to be specified for an attribute as illustrated by the following create table statement:![]() The default value of the tot_cred attribute is declared to be 0. As a result, when a tuple is insert into the athlete relation, if no value is provided for the tot_cred attribute, its value is set to 0. The following insert statement illustrates how an insertion can omit the value for the tot_cred attribute.
The default value of the tot_cred attribute is declared to be 0. As a result, when a tuple is insert into the athlete relation, if no value is provided for the tot_cred attribute, its value is set to 0. The following insert statement illustrates how an insertion can omit the value for the tot_cred attribute.![]()
1.3 Index Creation
Many queries reference only a small proportion of the records in a file. For example, a query like “Find all instructors in the Physics department” or “Find the tot_cred value of the student with ID 22201″ references only a fraction of the student records. It is inefficient for the system to read every record and to check ID field for the ID “32556,” or the building field for the value “Physics”.
An index on an attribute of a relation is a data structure that allows the database system to find those tuples in the relation that have a specified value for that attribute efficiently, without scanning through all the tuples of the relation. For example, if we create index on attribute ID of relation student, the database system can find the record with any specified ID value, such as 22201, or 44553, directly, without reading all the tuples of the student relation. An index can also be created on a list of attributes, for example on attributes name, and dept_name of student.
Although the SQL language does not formally define any syntax for creating indices, many databases support index creation using the syntax illustrated below. The above statement creates an index named studentID_index on the attribute ID of the relation student. When a user submit an SQL query that can benefit from using an index, the SQL query processor automatically uses the index. For example, given an SQL query that selects the student tuple with ID 22201, the SQL query processor would use the index studentID_index defined above to find the required tuple without reading the whole relation.
The above statement creates an index named studentID_index on the attribute ID of the relation student. When a user submit an SQL query that can benefit from using an index, the SQL query processor automatically uses the index. For example, given an SQL query that selects the student tuple with ID 22201, the SQL query processor would use the index studentID_index defined above to find the required tuple without reading the whole relation.
1.4 Large-Object Types
Many current-generation database applications need to store attributes that can be large (of the order of many kilobytes), such as a photograph, or very large (of the order of many megabytes or even gigabytes), such as a high-resolution medical image or video clip. SQL therefore provides large-object data types for character data (clob) and binary data (blob). The letters “lob” in these data types stand for “Large Object.” For example, we may declare attributes For result tuples containing large objects (multiple megabytes to gigabytes), it is inefficient or impractical to retrieve an entire large object into memory. Instead, an application would usually use an SQL query to retrieve a “locator” for a large object and then use the locator to manipulate the object from the host language in which the application itself is written. For instance, the JDBC application program interface permits a locator to be fetched instead of the entire large object; the locator can then be used to fetch the large object in small pieces, rather than all at once, much like reading data from an operating system file using a read function call.
For result tuples containing large objects (multiple megabytes to gigabytes), it is inefficient or impractical to retrieve an entire large object into memory. Instead, an application would usually use an SQL query to retrieve a “locator” for a large object and then use the locator to manipulate the object from the host language in which the application itself is written. For instance, the JDBC application program interface permits a locator to be fetched instead of the entire large object; the locator can then be used to fetch the large object in small pieces, rather than all at once, much like reading data from an operating system file using a read function call.
1.5 User-Defined Types
SQL supports two forms of user-defined data types. The first form, which we cover here, is called distinct types. The other form, called structured data types, allows the creation of complex data types with nested record structures, arrays, and multisets.
It is possible for several attributes to have the same data type. For example, the name attributes for student name and instructor name might have the same domain: the set of all person names. However, the domains of budget and dept_name certainly ought to be distinct. It is perhaps less clear whether name and dept_name should have the same domain. At the implementation level, both instructor names and department names are character strings. However, we would normally not consider the query “Find all instructors who have the same name as a department” to be a meaningful query. Thus, if we view the database at the conceptual, rather than the physical, level, name and dept_name should have distinct domains.
More importantly, at a practical level, assigning an instructor’s name to a department name is probably a programming error; similarly, comparing a monetary value expressed in dollars directly with a monetary value expressed in pounds is also almost surely a programming error. A good type system should be able to detect such assignments or comparisons. To support such checks, SQL provides the notion of distinct types.
The create type clause can be used to define new types. For example, the statements: define the user-defined Dollars and Pounds to be decimal numbers with a total of 12 digits, two of which are placed after the decimal point. The newly created types can then be used, for example, as types of attributes of relations. For example, we can declare the department table as:
define the user-defined Dollars and Pounds to be decimal numbers with a total of 12 digits, two of which are placed after the decimal point. The newly created types can then be used, for example, as types of attributes of relations. For example, we can declare the department table as: An attempt to assign a value of type Dollars to a variable of type Pounds results in a compile-time error, although both are of the same numeric type. Such an assignment is likely to be due to a programmer error, where the programmer forgot about the differences in currency. Declaring different types for different currencies helps catch such errors.
An attempt to assign a value of type Dollars to a variable of type Pounds results in a compile-time error, although both are of the same numeric type. Such an assignment is likely to be due to a programmer error, where the programmer forgot about the differences in currency. Declaring different types for different currencies helps catch such errors.
As a result of strong type checking, the expression (department.budget+20) would not be accepted since the attribute and the integer constant 20 have different types. Values of one type can be cast (that is, converted) to another domain, as illustrated below:![]() we could do addition on the numeric type, but to save the result back to an attribute of type Dollars we would have to use another cast expression to convert the type back to Dollars. SQL provides drop type and alter type clauses to drop or modify types that have been created earlier. Even before user-defined types were added to SQL (in SQL:1999), SQL had a similar but subtly different notion of domain (introduced in SQL-92), which can add integrity constraints to an underlying type. For example, we could define a domain DDollars as follows.
we could do addition on the numeric type, but to save the result back to an attribute of type Dollars we would have to use another cast expression to convert the type back to Dollars. SQL provides drop type and alter type clauses to drop or modify types that have been created earlier. Even before user-defined types were added to SQL (in SQL:1999), SQL had a similar but subtly different notion of domain (introduced in SQL-92), which can add integrity constraints to an underlying type. For example, we could define a domain DDollars as follows.![]() The domain DDollars can be used as an attribute type, just as we used the type Dollars. However, there are two significant differences between types and domains:
The domain DDollars can be used as an attribute type, just as we used the type Dollars. However, there are two significant differences between types and domains:
- Domains can have constraints, such as not null, specified on them, and can have default values defined for variables of the domain type, whereas user-defined types cannot have constraints or default values specified on them. User-defined types are designed to be used not just for specifying attribute types, but also in procedural extensions to SQL where it may not be possible to enforce constraints.
- Domains are not strongly types. As a result, values of one domain type can be assigned to values of another domain type as long as the underlying types are compatible.
When applied to domain, the check clause permits the schema designer to specify a predicate that must be satisfied by any attribute declared to be form this domain. For instance, a check clause can ensure that an instructor’s salary domain allows only values greater than a specified value: The domain YearlySalary has a constraint that ensures that the YearlySalary is greater than or equal to $29000.00. The clause constraint salary_value_test is optional, and is used to give the name salary_value-test to the constraint. The name is used by the system to indicate the constraint that an update violated. As another example, a domain can be restricted to contain only a specified set of values by using the in clause:
The domain YearlySalary has a constraint that ensures that the YearlySalary is greater than or equal to $29000.00. The clause constraint salary_value_test is optional, and is used to give the name salary_value-test to the constraint. The name is used by the system to indicate the constraint that an update violated. As another example, a domain can be restricted to contain only a specified set of values by using the in clause:
 1.6 Create Table Extensions
1.6 Create Table Extensions
Applications often require creation of tables that have the same schema as an existing table. SQL provides a create table like extension to support this task:![]() The above statement creates a new table temp_instructor that has the same schema as instructor. When writing a complex query, it is often useful to store the result of a query as a new table; the table is usually temporary. Two statements are required, one to create the table (with appropriate columns) and the second to insert the query result into the table. SQL:2003 provides as simpler technique to create a table containing the results of a query. For example the following statement creates a table t1 containing the results of a query.
The above statement creates a new table temp_instructor that has the same schema as instructor. When writing a complex query, it is often useful to store the result of a query as a new table; the table is usually temporary. Two statements are required, one to create the table (with appropriate columns) and the second to insert the query result into the table. SQL:2003 provides as simpler technique to create a table containing the results of a query. For example the following statement creates a table t1 containing the results of a query. By default, the names and data types of the columns are interred from the query result. Names can be explicitly given to the columns by listing the column names after the relation name.
By default, the names and data types of the columns are interred from the query result. Names can be explicitly given to the columns by listing the column names after the relation name.
As defined by the SQL:2003 standard, if the with data clause is omitted, the table is created but not populated with data. However many implementations populate the table with data by default even if the with data clause is omitted. Note that several implementations support the functionality of create table . . . like and create table . . . as using different syntax; see the respective system manuals for further details. The above create table . . . as statement closely resembles the create view statement and both are defined by using queries. The main difference is that the contents of the table are set when the table is created, whereas the contents of a view always reflect the current query result.
1.7 Schemas, Catalogs, and Environments
To understand the motivation for schemas and catalogs, consider how files are name in a file system. Early file systems were flat; that is, all files were stored in a single directory. Current file systems, of course, have a directory (or, synonymously, folder) structure, with files stored within subdirectories. To name a file uniquely, we must specify the full path name of the file, for example, /users/avi/db-look/chapter3.tex.
Like early file system, early database systems also had a single name space for all relations. User had to coordinate to make sure they did not try to use the same name for different relations. Contemporary database systems provide a three-level hierarchy for naming relations. The top level of the hierarchy consists of catalogs, each of which can contain schemas. SQL objects such as relations and views are contained within a schema. (Some database implementations use the term “database” in place of the term catalog.)
In order to perform any actions on a database, a user (or a program) must first connect to the database. The user must provide the user name and usually, a password for verifying the identity of the user. Each user has a default catalog and schema, and the combination is unique to the user. When a user connects to a database system, the default catalog and schema are set up for the connection; this corresponds to the current directory being set to the user’s home directory when the user logs into an operating system.
To identify a relation uniquely, a three-part name may be used, for example,![]() We may omit the catalog component, in which case the catalog part of the name is considered to be the default catalog for the connection. Thus if catalog5 is the default catalog, we can use univ_schema.course to identify the same relation uniquely. If a user wishes to access a relation that exists in a different schema than the default schema for that user, the name of the schema must be specified. However, if a relation is in the default schema for a particular user, then even the schema name may be omitted. Thus we can use just course if the default catalog is catalog5 and the default schema is univ_schema. With multiple catalogs and schemas available, different applications and different users can work independently without worrying about name clashes. Moreover, multiple versions of an application——one a production version, other test versions——can run on the same database system.
We may omit the catalog component, in which case the catalog part of the name is considered to be the default catalog for the connection. Thus if catalog5 is the default catalog, we can use univ_schema.course to identify the same relation uniquely. If a user wishes to access a relation that exists in a different schema than the default schema for that user, the name of the schema must be specified. However, if a relation is in the default schema for a particular user, then even the schema name may be omitted. Thus we can use just course if the default catalog is catalog5 and the default schema is univ_schema. With multiple catalogs and schemas available, different applications and different users can work independently without worrying about name clashes. Moreover, multiple versions of an application——one a production version, other test versions——can run on the same database system.
The default catalog and schema are part of an SQL environment that is set up for each connection. The environment additionally contains the user identifier (also referred to as the authorization identifier). All the usual SQL statements, including the DDL and DML statements, operate in the context of a schema. We can create and drop schemas by means of create schema and drop schema statements. In most database systems, schemas are also created automatically when user accounts are created, with the schema name set to the user account name. The schema is created in either a default catalog, or a catalog specified in creating the user account. The newly created schema becomes the default schema for the user account. Creation and dropping of catalogs is implementation dependent and not part of the SQL standard.
2、Authorization
We may assign a user several forms of authorizations on parts of the database. Authorizations on data include:
- Authorization to read data.
- Authorization to insert new data.
- Authorization to update data.
- Authorization to delete data.
Each of these types of authorizations is called a privilege. We may authorize the user all, none, or a combination of these types of privileges on specified parts of a database, such as a relation or a view. When a user submits a query or an update, the SQL implementation first checks if the query or update is authorized, based on the authorizations that the user has been granted. If the query or update is not authorized, it is rejected.
In addition to authorizations on data, users may also be granted authorizations on the database schema, allowing them, for example, to create, modify, or drop relations. A user who has some form of authorization may be allowed to pass on (grant) this authorization to other users, or to withdraw (revoke) an authorization that was granted earlier. In this section, we see how each of these authorizations can be specified in SQL. The ultimate form of authority is that given to the database administrator. The database administrator may authorize new users, restructure the database, and so on. This form of authorization is analogous to that of a superuser, administrator, or operator for an operating system.
2.1 Granting and Revoking of Privileges
The SQL standard includes the privileges select, insert, update, and delete. The privilege all privileges can be used as a short form for all the allowable privileges. A user who creates a new relation is given all privileges on that relation automatically. The SQL data-definition language includes commands to grant and revoke privileges. The grant statement is used to confer authorization. The basic form of this statement is: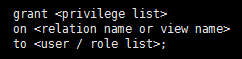
The privilege list allows the granting of several privileges in one command. The select authorization on a relation is required to read tuples in the relation. The following grant statement grants database users wey and zhf select authorization on the department relation:![]() This allows those users to run queries on the department relation. The update authorization on a relation allows a user to update any tuple in the relation. The update authorization may be given either on all attributes of the relation or on only some. If update authorization is included in a grant statement, the list of attributes on which update authorization is to be granted optionally appears in parentheses immediately after the update keyword. If the list of attributes is omitted, the update privilege will be granted on all attributes of the relation.
This allows those users to run queries on the department relation. The update authorization on a relation allows a user to update any tuple in the relation. The update authorization may be given either on all attributes of the relation or on only some. If update authorization is included in a grant statement, the list of attributes on which update authorization is to be granted optionally appears in parentheses immediately after the update keyword. If the list of attributes is omitted, the update privilege will be granted on all attributes of the relation.
This grant statement gives users wey and zhf update authorization on the budget attribute of the department relation:![]() The insert authorization on a relation allows a user to insert tuples into the relation. The insert privilege may also specify a list of attributes; any inserts to the relation must specify only these attributes, and the system either gives each of the remaining attributes default values (if a default is defined for the attribute) or sets them to null. The delete authorization on a relation allows a user to delete tuples from a relation.
The insert authorization on a relation allows a user to insert tuples into the relation. The insert privilege may also specify a list of attributes; any inserts to the relation must specify only these attributes, and the system either gives each of the remaining attributes default values (if a default is defined for the attribute) or sets them to null. The delete authorization on a relation allows a user to delete tuples from a relation.
The user name public refers to all current and future users of the system. Thus, privileges granted to public are implicitly granted to all current and future users. By default, a user / role that is granted a privilege is not authorized to grant that privilege to another user / role. SQL allows a privilege grant to specify that the recipient may further grant the privilege to another user.
It is worth noting that the SQL authorization mechanism grants privileges on an entire relation, or on specified attributes of a relation. However, it does not permit authorizations on specific tuples of a relation. To revoke an authorization, we use the revoke statement. It takes a form almost identical to that of grant: Thus, to revoke the privileges that we granted previously, we write
Thus, to revoke the privileges that we granted previously, we write![]()
![]() Revocation of privileges is more complex if the user from whom the privilege is revoked has granted the privilege to another user.
Revocation of privileges is more complex if the user from whom the privilege is revoked has granted the privilege to another user.
2.2 Roles
Consider the real-world roles of various people in a university. Each instructor must have the same types of authorizations on the same set of relations. Whenever a new instructor is appointed, she will have to be given all these authorizations individually. A better approach would be to specify the authorizations that every instructor is to be given, and to identify separately which database users are instructors. The system can use these two pieces of information to determine the authorizations of each instructor. When a new instructor is hired, a user identifier must be allocated to him, and he must be identified as an instructor. Individual permissions given to instructors need not be specified again.
The notion of roles captures this concept. A set of roles is created in the database. Authorizations can be granted to roles, in exactly the same fashion as they are ground to individual users. Each database user is granted a set of roles (which may be empty) that she is authorized to perform. In our university database, examples of roles could include instructor, teaching_assistant, student, dean, and department_chair.
A less preferable alternative would be to create an instructor userid, and permit each instructor to connect to the database using the instructor userid. The problem with this approach is that it would not be possible to identify exactly which instructor carried out a database update, leading to security risks. The use of roles has the benefit of requiring users to connect to the database with their own userid.
Any authorization that can be granted to a user can be granted to a role. Roles are granted to users just as authorizations are. Roles can be created in SQL as follows:![]() Roles can then be granted privileges just as the users can, as illustrated in this statement:
Roles can then be granted privileges just as the users can, as illustrated in this statement:![]() Roles can be granted to users, as well as to other roles, as these statements show:
Roles can be granted to users, as well as to other roles, as these statements show: Thus the privileges of a user or a role consist of:
Thus the privileges of a user or a role consist of:
- All privileges directly granted to the user / role.
- All privileges granted to roles that have been granted to the user / role.
Note that there can be a chain of roles; for example, the role teaching_assistant may be granted to all instructors. In turn the role instructor is granted to all deans. Thus, the dean role inherits all privileges granted to the roles instructors and to teaching_assistant in addition to privileges granted directly to dean.
When a user logs in to the database system, the actions executed by the user during that session have all the privileges granted directly to the user, as well as all privileges granted to roles that are granted (directly or indirectly via other roles) to that user. Thus, if a user Amit has been granted the role dean, user Amit holds all privileges granted directly to Amit, as well as privileges granted to dean, plus privileges granted to instructor, and teaching_assistant if, as above, those roles were granted (directly or indirectly) to the role dean.
It is worth noting that the concept of role-based authorization is not specific to SQL, and role-based authorization is used for access control in a wide variety of shared applications.
2.3 Authorization on Views
In our university example, consider a staff member who needs to know the salaries of all faculty in a particular department, say the Geology department. This staff member is not authorized to see information regarding faculty in other departments. Thus, the staff member must be denied direct access to the instructor relation. But, if he is to have access to the information for the Geology department, he might be granted access to a view that we shall call geo_instructor, consisting of only those instructor tuples pertaining to the Geology department. This view can be defined in SQL as follows:![]() Suppose that the staff member issues the following SQL query:
Suppose that the staff member issues the following SQL query:![]() Clearly, the staff member is authorized to see the result of this query. However, when the query processor translates it into a query on the actual relations in the database, it produces a query on instructor. Thus, the system must check authorization on the clerk’s query before it begins query processing.
Clearly, the staff member is authorized to see the result of this query. However, when the query processor translates it into a query on the actual relations in the database, it produces a query on instructor. Thus, the system must check authorization on the clerk’s query before it begins query processing.
A user who creates a view does not necessarily receive all privileges on that view. She receives only those privileges that provide no additional authorization beyond those that she already had. For example, a user who creates a view cannot be given update authorization on a view without having update authorization on the relations used to define the view. If a user creates a view on which no authorization can be granted, the system will deny the view creation request. In our geo_instructor view example, the creator of the view must have select authorization on the instructor relation.
As we will see later, SQL supports the creation of functions and procedures, which may in turn contain queries and updates. The execute privilege can be granted on a function or procedure, enabling a user to execute the function / procedure. By default, just like views, functions and procedures have all the privileges that the creator of the function or procedure had. In effect, the function or procedure runs as if it were invoked by the user who created the function.
Although this behavior is appropriate in many situations, it is not always appropriate. Starting with SQL:2003, if the function definition has an extra clause sql security invoker, then it is executed under the privileges of the user who invokes the function, rather than the privileges of the definer of the function. This allows the creation of libraries of functions that can run under the same authorization as the invoker.
2.4 Authorizations on Schema
The SQL standard specifies a primitive authorization mechanism for the database schema: Only the owner of the schema can carry out any modification to the schema, such as creating or deleting relations, adding or dropping attributes of relations, and adding or dropping indices. However, SQL includes a references privilege that permits a user to declare foreign keys when creating relations. The SQL references privilege is granted on specific attributes in a manner like that for the update privilege. The following grant statement allows user wey to create relations that reference the key branch_name of the branch relation as a foreign key:![]() Initially, it may appear that there is no reason ever to prevent users from creating foreign keys referencing another relation. However, recall that foreign-key constraints restrict deletion and update operations on the referenced relation. Suppose wey creates a foreign key in a relation r referencing the dept_name attribute of the department relation and then inserts a tuple into r pertaining to the Geology department. It is no longer possible to delete the Geology department from the department relation without also modifying relation r. Thus, the definition of a foreign key by wey restricts future activity by other users; therefore, there is a need for the references privilege.
Initially, it may appear that there is no reason ever to prevent users from creating foreign keys referencing another relation. However, recall that foreign-key constraints restrict deletion and update operations on the referenced relation. Suppose wey creates a foreign key in a relation r referencing the dept_name attribute of the department relation and then inserts a tuple into r pertaining to the Geology department. It is no longer possible to delete the Geology department from the department relation without also modifying relation r. Thus, the definition of a foreign key by wey restricts future activity by other users; therefore, there is a need for the references privilege.
Continuing to use the example of the department relation, the references privilege on department is also required to create a check constraint on a relation r if the constraint has a subquery referencing department. This is reasonable for the same reason as the one we gave for foreign-key constraints; a check constraint that references a relation limits potential updates to that relation.
2.5 Transfer of Privileges
A user who has been granted some form of authorization may be allowed to pass on this authorization to other users. By default, a user / role that is granted a privilege is not authorized to grant that privilege to another user / role. If we wish to grant a privilege and to allow the recipient to pass the privilege on to other users, we append the with grant option clause to the appropriate grant command. For example, if we wish to allow zhf the select privilege on department and allow zhf to grant this privilege to others, we write:![]() The creator of an object (relation/view/role) holds all privileges on the object, including the privilege to grant privileges to others. Consider, as an example, the granting of update authorization on the teaches relation of the university database. Assume that, initially, the database administrator grants update authorization on teaches to users U1, U2 and U3, who may in turn pass on this authorization to other users. The passing of a specific authorization from one user to another can be represented by an authorization graph. The nodes of this graph are the users.
The creator of an object (relation/view/role) holds all privileges on the object, including the privilege to grant privileges to others. Consider, as an example, the granting of update authorization on the teaches relation of the university database. Assume that, initially, the database administrator grants update authorization on teaches to users U1, U2 and U3, who may in turn pass on this authorization to other users. The passing of a specific authorization from one user to another can be represented by an authorization graph. The nodes of this graph are the users.
Consider the graph for update authorization on teaches. The graph includes an edge Ui -> Uj if user Ui grant update authorization on teaches to Uj. The root of the graph is the database administrator. In the sample graph in Figure 1, observe that user U5 is granted authorization by both U1 and U2; U4 is granted authorization by only U1.  Figure 1 Authorization-grant graph (U1, U2, . . . , U5 are users and DBA refers to the database administrator).
Figure 1 Authorization-grant graph (U1, U2, . . . , U5 are users and DBA refers to the database administrator).
A user has an authorization if and only if there is a path from the root of the authorization graph (the node representing the database administrator) down to the node representing the user.
2.6 Revoking of Privileges
Suppose that the database administrator decides to revoke the authorization of user U1. Since U4 has authorization from U1, that authorization should be revoked as well. However, U5 was granted authorization by both U1 and U2. Since the database administrator did not revoke update authorization on teaches from U2, U5 retains update authorization on teaches. If U2 eventually revokes authorization from U5, then U5 loses the authrization.
A pair of devious users might attempt to defeat the rules for revocation of authorization by granting authorization to each other. For example, if U2 is initially granted an authorization by the database administrator, and U2 further grants it to U3. Suppose U3 now grants the privilege back to U2. If the database administrator revokes authorization from U2, it might appear that U2 retains authorization through U3. However, note that once the administrator revokes authorization from U2, there is no path in the authorization graph from the root to either U2 or to U3. Thus, SQL ensures that the authorization is revoked from both the users.
As we just saw, revocation of a privilege from a user / role may cause other users / roles also to lose that privilege. This behavior is called cascading revocation. In most database systems, cascading is the default behavior. However, the revoke statement may specify restrict in order to prevent cascading revocation: In this case, the system returns an error if there are any cascading revocations, and does not carry out the revoke action. The keyword cascade can be used instead of restrict to indicate that revocation should cascade; however, it can be omitted, as we have done in the preceding examples, since it is the default behavior. The following revoke statement revokes only the grant option, rather than the actual select privilege:
In this case, the system returns an error if there are any cascading revocations, and does not carry out the revoke action. The keyword cascade can be used instead of restrict to indicate that revocation should cascade; however, it can be omitted, as we have done in the preceding examples, since it is the default behavior. The following revoke statement revokes only the grant option, rather than the actual select privilege:![]() Note that some database implementations do not support the above syntax; instead, the privilege itself can be revoked, and then granted again without the grant option.
Note that some database implementations do not support the above syntax; instead, the privilege itself can be revoked, and then granted again without the grant option.
Cascading revocation is inappropriate in many situations. Suppose Satoshi has the role of dean, grants instructor to Amit, and later the role dean is revoked from Satoshi (perhaps because Satoshi leaves the university); Amit continues to be employed on the faculty, and should retain the instructor role. To deal with the above situation, SQL permits a privilege to be granted by a role rather than by a user. SQL has a notion of the current role associated with a session. By default, the current role associated with a session is null (except in some special cases). The current role associated with a session can be set by executing set role role_name. The specified role must have been granted to the user, else the set role statement fails.
To grant a privilege with the grantor set to the current role associated with a session, we can add the clause:![]() to the grant statement, provided the current role is not null. Suppose the granting of the role instructor (or other privileges) to Amit is done using the granted by current_role clause, with the current role set to dean, instead of the grantor being the user Satoshi. Then, revoking of roles / privileges (including the role dean) from Satoshi will not result in revoking of privileges that had the grantor set to the role dean, even if Satoshi was the user who executed the grant; thus, Amit would retain the instructor role even after Satoshi’s privileges are revoked.
to the grant statement, provided the current role is not null. Suppose the granting of the role instructor (or other privileges) to Amit is done using the granted by current_role clause, with the current role set to dean, instead of the grantor being the user Satoshi. Then, revoking of roles / privileges (including the role dean) from Satoshi will not result in revoking of privileges that had the grantor set to the role dean, even if Satoshi was the user who executed the grant; thus, Amit would retain the instructor role even after Satoshi’s privileges are revoked.
3、Summary
- SQL supports several types of joins including inner and outer joins and several types of join conditions.
- View relations can be defined as relations containing the result of queries. Views are useful for hiding unneeded information, and for collecting together information from more than one relation into a single view.
- Transactions are a sequence of queries and updates that together carry out a task. Transactions can be committed, or rolled back; when a transaction is rolled back, the effects of all updates performed by the transaction are undone.
- Integrity constraints ensure that changes made to the database by authorized users do not result in a loss of data consistency.
- Referential-integrity constraints ensure that a value that appears in one relation for a given set of attributes also appears for a certain set of attributes in another relation.
- Domain constraints specify the set of possible values that may be associated with an attribute. Such constraints may also prohibit the use of null values for particular attributes.
- Assertions are declarative expressions that state predicates that we require always to be true.
- The SQL data-definition language provides support for defining built-in domain types such as date and time, as well as user-defined domain types.
- SQL authorization mechanisms allow one to differentiate among the users of the database as far as the type of access they are permitted on various data values in the database.
- A user who has been granted some form of authority may be allowed to pass on this authority to other users. However, we must be careful about how authorization can be passed among users if we are to ensure that such authorization can be revoked at some future time.
- Roles help to assign a set of privileges to a user according to the role that teh user plays in the organization.