
In previous series, we provided detailed coverage of the basic structure of SQL. In this series, we cover some of the the more advanced features of SQL. We address the issue of how to access SQL from a general-purpose programming language, which is very important for building applications that use a database to store database, either by extending the SQL language to support procedural actions, or by allowing functions defined in procedural languages to be executed within the database. We describe triggers, which can be used to specify actions that are to be carried out automatically on certain events such as insertion, deletion, or update of tuples in a specified relation. We discuss recursive queries and advanced aggregation features supported by SQL. Finally, we describe online analytic processing (OLAP) systems, which support interactive analysis of very large datasets.
1、Accessing SQL From a Programming Language
SQL provides a powerful declarative query language. Writing queries in SQL is usually much easier than coding the same queries in a general-purpose programming language. However, a database programmer must have access to a general-purpose programming language for at least two reasons:
- Not all queries can be expressed in SQL, since SQL does not provide the full expressive power of a general-purpose language. That is, there exist queries that can be expressed in a language such as C, Java, or Cobol that cannot be expressed in SQL. To write such queries, we can embed SQL within a more powerful language.
- Nondeclarative actions—such as printing a report, interacting with a user, or sending the results of a query to a graphical user interface—cannot be done from within SQL. Applications usually have several components, and querying or updating data is only one component; other components are written in general-purpose programming languages. For an integrated application, there must be a means to combine SQL with a general-purpose programming language.
There are two approaches to accessing SQL from a general-purpose programming language:
- Dynamic SQL: A general-purpose program can connect to and communicate with a database server using a collection of functions (for procedural languages) or methods (for object-oriented languages). Dynamic SQL allows the program to construct an SQL query as a character string at runtime, submit the query, and then retrieve the result into program variables a tuple at a time. The dynamic SQL component of SQL allows programs to construct and submit SQL queries at runtime. In this section, we look at two standards for connecting to an SQL database and performing queries and updates. One, JDBC, is an application program interface for the Java language. The other, ODBC is an application program interface originally developed for the C language, and subsequently extended to other languages such as C++, C#.
- Embedbed SQL: Like dynamic SQL, embedded SQL provides a means by which a program can interact with a database server. However, under embedded SQL, the SQL statements are identified at compile time using a preprocessor. The preprocessor submits the SQL statements to the database system for precompilation and optimization; then it replaces the SQL statements in the application program with appropriate code and function calls before invoking the programming-language compiler.
A major challenge in mixing SQL with a general-purpose language is the mismatch in the ways these languages manipulate data. In SQL, the primary type of data is the relation. SQL statements operate on relations and return relations as a result. Programming language normally operate on a variable at a time, and those variables correspond roughly to the value of an attribute in a tuple in a relation. Thus, integrating these two types of languages into a single application requires providing a mechanism to return the result of a query in a manner that the program can handle.
1.1 JDBC
The JDBC standard defines an application program interface (API) that Java programs can use to connect to database servers. (The word JDBC was originally an abbreviation for Java Database Connectivity, but the full form is no longer used.) Figure 1 shows an example Java program that uses the JDBC interface. It illustrates how connections are opened, how statements are executed and results processed, and how connections are closed. We discuss this example in detail in this section. The Java program must import java.sql.*, which contains the interface definitions for the functionality provided by JDBC.
Figure 1 An example of JDBC code.
1.1.1 Connecting to the Database
The first step in accessing a database from a Java program is to open a connection to the database. This step is required to select which database to use, for example, an instance of Oracle running on your machine, or a PostgreSQL database running on another machine. Only after opening a connection can a Java program execute SQL statements. A connection is opened using the getConnection method of the Driver-Manager class (within java.sql). This method takes three parameters.
- The first parameter to the getConnection call is a string that specifies the URL, or machine name, where the server runs (in our example, db.yale.edu), along with possibly some other information such as the protocol to be used to communicate with the database (in our example, jdbc:oracle:thin:; we shall shortly see why this is required), the port number the database system uses for communication (in our example, 2000), and the specific database on the server to be used (in our example, univdb). Note that JDBC specifies only the API, not the communication protocol. A JDBC driver may support multiple protocols, and we must specify one supported by both the database and the driver. The protocol details are vendor specific.
- The second parameter to getConnection is a database user identifier, which is a string.
- The third parameter is a password, which is also a string. (Note that the need to specify a password within the JDBC code presents a security risk if an unauthorized person accesses your Java code.)
In our example in the figure, we have created a Connection object whose handle is conn. Each database product that supports JDBC (all the major database vendors do) provides a JDBC driver that must be dynamically loaded in order to access the database from Java. In fact, loading the driver must be done first, before connecting to the database. This is done by invoking Class.forName with one argument specifying a concrete class implementing the java.sql.Driver interface, in the first line of the program in Figure 1. This interface provides for the translation of product-independent JDBC calls into the product-specific calls needed by the specific database management system being used. The example in the figure shows the Oracle driver, oracle.jdbc.driver.OracleDriver. The driver is available in a .jar file at vendor Web sites and should be placed within the classpath so that the Java compiler can access it.
The actual protocol used to exchange information with the database depends on the driver that is used, and is not defined by the JDBC standard. Some drivers support more than one protocol, and a suitable protocol must be chosen depending on what protocol the database that you are connecting to supports. In our example, when opening a connection with the database, the string jdbc:oracle:thin:specifies a particular protocol supported by Oracle.
1.1.2 Shipping SQL Statements to the Database System
Once a database connection is open, the program can use it to send SQL statements to the database system for execution. This is done via an instance of the class Statement. A Statement object is not the SQL statement itself, but rather an object that allows the Java program to invoke methods that ship an SQL statement givens as an argument for execution by the database system. Our example creates a Statement handle (stmt) on the connection conn.
To execute a statement, we invoke either the executeQuery method or the executeUpdate method, depending on whether the SQL statement is a query (and, thus, returns a result set) or nonquery statement such as update, insert, delete, create table, etc. In our example, stmt.executeUpdate executes an update statement that inserts into the instructor relation. It returns an integer giving the number of tuples inserted, updated, or deleted. For DDL statements, the return value is zero. The try { . . . } catch { . . . } construct permits us to catch any exceptions (error conditions) that arise when JDBC calls are made, and print an appropriate message to the user.
1.1.3 Retrieving the Result of a Query
The example program executes a query by using stmt.executeQuery. It retrieves the set of tuples in the result into a ResultSet object rset and fetches them one tuple at a time. The next method on the result set tests whether or not there remains at least one unfetched tuple in the result set and if so fetches it. The return value of the next method is a Boolean indicating whether it fetched a tuple. Attributes from the fetched tuple are retrieved using various methods whose names begin with get. The method getString can retrieve any of the basic SQL data types (converting the value to a Java String object), but more restrictive methods such as getFloat can be used as well. The argument to the various get methods can either be an attribute name specified as a string, or an integer indicating the position of the desired attribute within the tuple. Figure 1 shows two ways of retrieving the values of attributes in a tuple: using the name of the attribute (dept_name) and using the position of the attribute (2, to denote the second attribute).
The statement and connection are both closed at the end of the Java program. Note that it is important to close the connection because there is a limit imposed on the number of connections to the database; unclosed connections may cause that limit to be exceeded. If this happens, the application cannot open any more connections to the database.
1.4 Prepared Statements
We can create a prepared statement in which some values are replaced by “?”, thereby specifying that actual values will be provided later. The database system compiles the query when it is prepared. Each time the query is executed (with new values to replace the “?”s), then database system can reuse the previously compiled form of the query and apply the new values. The code fragment in Figure 2 shows how prepared statements can be used.
 Figure 2 Prepared statements in JDBC code.
Figure 2 Prepared statements in JDBC code.
The prepareStatement method of the Connection class submits an SQL statement for compilation. It returns an object of class PreparedStatement. At this point, no SQL statement has been executed. The executeQuery and executeUpdate methods of PreparedStatement class do that. But before they can be invoked, we must use methods of class PreparedStatement that assign values for the “?” parameters. The setString method and other similar methods such as setInt for other basic SQL types allow us to specify the values for the parameters. The first argument specifies the “?” parameter for which we are assigning a value (the first parameter is 1, unlike most other Java constructs, which start with 0). The second argument specifies the value to be assigned.
In the example in the figure, we prepare an insert statement, set the “?” parameters, and then invoke executeUpdate. The final two lines of our example show that parameter assignments remain unchanged until we specifically reasign them. Thus, the final statement, which invokes executeUpdate, inserts the tuple (“88878”, “Perry”, “Finance”, 125000).
Prepared statements allow for more efficient execution in cases where the same query can be compiled once and then run multiple times with different parameter values. However, there is an even more significant advantage to prepared statements that makes them the preferred method of executing SQL queries whenever a user-entered value is used, even if the query is to be run only once. Suppose that we read in a user-entered value and then use Java string manipulation to construct the SQL statement. If the user enters certain special characters, such as a single quote, the resulting SQL statement may be syntactically incorrect unless we take extraordinary care in checking the input. The setString method does this for us automatically and inserts the needed escape characters to ensure syntactic correctness.
In our example, suppose that the values for the variables ID, name, dept_name, and salary have been entered by a user, and a corresponding row is to be inserted into the instructor relation. Suppose that, instead of using a prepared statement, a query is constructed by concatenating the strings using the following Java expression:![]() and the query is executed directly using the executeQuery method of a Statement object. Now, if the user typed a single quote in the ID or name fields, the query string would have a syntax error. It is quite possible that an instructor name may have a quotation mark in its name (for example, “O’Henry”). While the above example might be considered an annoyance, the situation can be much worse. A technique called SQL injection can be used by malicious hackers to steal data or damage the database. Suppose a Java program inputs a string name and constructs the query:
and the query is executed directly using the executeQuery method of a Statement object. Now, if the user typed a single quote in the ID or name fields, the query string would have a syntax error. It is quite possible that an instructor name may have a quotation mark in its name (for example, “O’Henry”). While the above example might be considered an annoyance, the situation can be much worse. A technique called SQL injection can be used by malicious hackers to steal data or damage the database. Suppose a Java program inputs a string name and constructs the query:![]() If the user, instead of entering a name, enters:
If the user, instead of entering a name, enters:![]() then the resulting statement becomes:
then the resulting statement becomes:![]() which is:
which is:![]() In the resulting query, the where clause is always true and the entire instructor relation is returned. More clever malicious users could arrange to output even more data. Use of a prepared statement would prevent this problem because the input string would have escape characters inserted, so the resulting query becomes:
In the resulting query, the where clause is always true and the entire instructor relation is returned. More clever malicious users could arrange to output even more data. Use of a prepared statement would prevent this problem because the input string would have escape characters inserted, so the resulting query becomes:![]() which is harmless and returns the empty relation. Older systems allow multiple statements to be executed in a single call, with statements separated by a semicolon. This feature is being eliminated because the SQL injection technique was used by malicious hackers to insert whole SQL statements. Because these statements run with the privileges of the owner of the Java program, devastating SQL statements such as drop table could be executed. Developers of SQL applications need to be wary of such potential security holes.
which is harmless and returns the empty relation. Older systems allow multiple statements to be executed in a single call, with statements separated by a semicolon. This feature is being eliminated because the SQL injection technique was used by malicious hackers to insert whole SQL statements. Because these statements run with the privileges of the owner of the Java program, devastating SQL statements such as drop table could be executed. Developers of SQL applications need to be wary of such potential security holes.
1.5 Callable Statements
JDBC also provides a CallableStatement interface that allows invocation of SQL stored procedures and functions. These play the same role for functions and procedures as prepareStatement does for queries.![]() The data types of function return values and out parameters of procedures must be registered using the method registerOutParameter(), and can be retrieved using get methods similar to those for result sets.
The data types of function return values and out parameters of procedures must be registered using the method registerOutParameter(), and can be retrieved using get methods similar to those for result sets.
1.6 Metadata Features
As we noted earlier, a Java application program does not include declarations for data stored in the database. Those declarations are part of the SQL DDL statements. Therefore, a Java program that uses JDBC must either have assumptions about the database schema hard-coded into the program or determine that information directly from the database system at runtime. The later approach is usually preferable, since it makes the application program more robust to changes in the database schema.
Recall that when we submit a query using the executeQuery method, the result of the query is contained in ResultSet object. The interface ResultSet has a method, getMetaData(), that returns a ResultSetMetaData object that contains metadata about the result set. ResultSetMetaData, in turn, has methods to find metadata information, such as the number of columns in the result, the name of a specified column, or the type of a specified column. In this way, we can execute a query even if we have no idea of the schema of the result.
The Java code segment below uses JDBC to print out the names and types of all columns of a result set. The variable rs in the code below is assumed to refer to a ResultSet instance obtained by executing a query.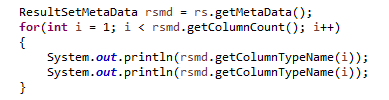 The getColumnCount method returns the arity (number of attributes) of the result relation. That allows us to iterate each attribute (note that we start at 1, as is conventional in JDBC). For each attribute, we retrieve its name and data type using the methods getColumnName and getColumnTypeName, respectively.
The getColumnCount method returns the arity (number of attributes) of the result relation. That allows us to iterate each attribute (note that we start at 1, as is conventional in JDBC). For each attribute, we retrieve its name and data type using the methods getColumnName and getColumnTypeName, respectively.
The DatabaseMetaData interface provides a way to find metadata about the database. The interface Connection has a method getMetaData that returns a DatabaseMetaData object. The DatabaseMetaData interface in turn has a very large number of methods to get metadata about the database and the database system to which the application is connected. For example, there are methods that return the product name and version number of the database system. Other methods allow the application to query the database system about its supported features. Still other methods return information about the database itself. The code in Figure 3 illustrates how to find information about columns (attributes) of relations in a database.
The variable conn is assumed to be a handle for an already opened database connection. The method getColumns takes four arguments: a catalog name (null signifies that the catalog name is to be ignored), a schema name pattern, a table name pattern, and a column name pattern. The schema name, table name, and column name patterns can be used to specify a name or a pattern. Patterns can use the SQL string matching special characters “%” and “-“; for instance, the pattern “%” matches all names. Only columns of tables of schemas satisfying the specified name or pattern are retrieved. Each row in the result set contains information about one column. The rows have a number of columns such as the name of the catalog, schema, table and column, the type of the column, and so on.
 Figure 3 Finding column information in JDBC using DatabaseMetaData.
Figure 3 Finding column information in JDBC using DatabaseMetaData.
Examples of other methods provided by DatabaseMetaData that provide information about the database include those for retrieval of metadata about relations (getTables()), foreign-key references (getCrossReference()), authorizations, database limits such as maximum number of connections, and so on. The metadata interfaces can be used for a variety of tasks. For example, they can be used to write a database browser that allows a user to find the tables in a database, examine their schema, examine rows in a table, apply selections to see desired rows, and so on. The metadata information can be used to make code used for these tasks generic; for example, code to display the rows in a relation can be written in such a way that it would work on all possible relations regardless of their schema. Similarly, it is possible to write code that takes a query string, executes the query, and prints out the results as a formatted table; the code can work regardless of the actual query submitted.
1.7 Other Features
JDBC provides a number of other features, such as updatable result sets. It can create an updatable result set from a query that performs a selection and / or a projection on a database relation. An update to a tuple in the result set then results in an update to the corresponding tuple of the database relation. Recall from previous section that a transaction allows multiple actions to be treated as a single atomic unit which can be committed or rolled back.
By default, each SQL statement is treated as a separate transaction that is committed automatically. The method setAutoCommit() in the JDBC Connection interface allows this behavior to be turned on or off. Thus, if conn is an open connection, conn.setAutoCommit(false) turns off automatic commit. Transactions must then be committed or rolled back explicitly using either conn.commit() or conn.rollback(). conn.setAutoCommit(true) turns on automatic commit.
JDBC provides interfaces to deal with large objects without requiring an entire large object to be created in memory. To fetch large objects, the ResultSet interface provides methods getBlob() and getClob() that are similar to the getString() method, but return objects of type Blob and Clob, respectively. These objects do not store the entire large object, but instead store “locators” for the large objects, that is, logical pointers to the actual large object in the database. Fetching data from these objects is very much like fetching data from a file or an input stream, and can be performed using methods such as getBytes and getSubString.
Conversely, to store large objects in the database, the PrepareStatement class permits a database column whose type is blob to be linked to an input stream (such as a file that has been opened) using the method setBlob(int parameterIndex, InputStream inputStream). When the prepared statement is executed, data are read from the input stream, and written to the blob in the database. Similarly, a clob cloumn can be set using the setClob method, which takes as arguments a parameter index and a character stream.
JDBC includes a row set feature that allows result sets to be collected and shipped to other applications. Row sets can be scanned both backward and forward and can be modified. Because row sets are not part of the database itself once they are downloaded, we do not cover details of their use here.
2、ODBC
The Open Database Connectivity (ODBC) standard defines an API that applications can use to open a connection with a database, send queries and updates, and get back results. Applications such as graphical user interfaces, statistics packages, and spreadsheets can make use of the same ODBC API to connect to any database server that supports ODBC.
Each database system supporting ODBC provides a library that must be linked with the client program. When the client program makes an ODBC API call, the code in the library communications with the server to carry out the requested action, and fetch results. Figure 4 shows an example of C code using the ODBC API. The first step in using ODBC to communicate with a server is to set up a connection with the server. To do so, the program first allocate an SQL environment, then a database connection handle. ODBC defines the types HENV, HDBC, and RETCODE. The program then opens the database connection by using SQLconnect. This call takes several parameters, including the connection handle, the server to which to connect, the user identifier, and the password for the database. The constant SQL_NTS denotes that the previous argument is a null-terminated string.
 Figure 4 ODBC code example.
Figure 4 ODBC code example.
Once the connection is set up, the program can send SQL commands to the database by using SQLExecDirect. C language variables can be bound to attributes of the query result, so that when a result tuple is fetched using SQLFetch, its attribute values are stored in corresponding C variables. The SQLBindCol function does this task; the second argument identifies the position of the attribute in the query result; and the third argument indicates the type conversion required from SQL to C. The next argument gives the address of the variable. For variable-length types like character arrays, the last two arguments give the maximum length of the variable and a location where the actual length is to be stored when a tuple is fetched. A negative value returned for the length field indicates that the value is null. For fixed-length types such as integer or float, the maximum length field is ignored, while a negative value returned for the length field indicates a null value.
The SQLFetch statement is in a while loop that is executed until SQLFetch returns a value other than SQL_SUCCESS. On each fetch, the program stores the values in C variables as specified by the calls on SQLBindCol and prints out these values. At the end of the session, the program frees the statement handle, disconnects from the database, and frees up the connection and SQL environment handles. Good programming style requires that the result of every function call must be checked to make sure there are no errors; we have omitted most of these checks for brevity.
It is possible to create an SQL statement with parameters; for example, consider the statement insert into department values (?, ?, ?). The question marks are placeholders for values which will be supplied later. The above statement can be “prepared,” that is, compiled at the database, and repeatedly executed by providing actual values for the placeholders—in this case, by providing an department name, building, and budget for the relation department.
ODBC defines functions for a variety of tasks, such as finding all the relations in the database and finding the names and types of columns of a query result or a relation in the database. By default, each SQL statement is treated as a separate transaction that is committed automatically. The SQLSetConnectOption(conn, SQL_AUTOCOMMIT, 0) turns off automatic commit on connection conn, and transactions must then be committed explicitly by SQLTransact(conn, SQL_COMMIT) or rolled back by SQLTransact(conn, SQL_ROLLBACK).
The ODBC standard defines conformance levels, which specify subsets of the functionality defined by the standard. An ODBC implementation may provide only core level features, or it may provide more advanced (level 1 or level 2) features. Level 1 requires support for fetching information about the catalog, such as information about what relations are present and the types of their attributes. Level 2 requires further features, such as the ability to send and retrieve arrays of parameter values and to retrieve more detailed catalog information. The SQL standard defines a call level interface (CLI) that is similar to the ODBC interface.