
We have already seen several functions that are built into the SQL language. In this section, we show how developers can write their own functions and procedures, store them in the database, and then invoke them from SQL statements.
1、Functions and Procedures
Functions are particularly useful with specialized data types such as images and geometric objects. For instance, a line-segment data type used in a map database may have an associated function that checks whether two line segments overlap, and an image data type may have associated functions to compare two images for similarity.
Procedures and functions allow “business logic” to be stored in the database, and executed from SQL statements. For example, universities usually have many rules about how many courses a student can take in a given semester, the minimum number of courses a full-time instructor must teach in a year, the maximum number of majors a student can be enrolled in, and so on. While such business logic can be encoded as programming-language procedures stored entirely outside the database, defining them as stored procedures in the database has several advantages. For example, it allows multiple applications to access the procedures, and it allows a single point of change in case the business rules change, without changing other parts of the application. Application code can then call the stored procedures, instead of directly updating database relations.
SQL allows the definition of functions, procedures, and methods. These can be defined either by the procedural component of SQL, or by an external programming language such as Java, C, or C++. Although the syntax we present here is defined by the SQL standard, most databases implement nonstandard versions of this syntax. For example, the procedural languages supported by Oracle (PL/SQL), Microsoft SQL Server (TransactSQL), and PostgreSQL (PL/pgSQL) all differ from the standard syntax we present here. Although parts of the syntax we present here may not be supported on such systems, the concepts we describe are applicable across implementations, although with a different syntax.
1.1 Declaring and Invoking SQL Functions and Procedures
Suppose that we want a function that, given the name of a department, returns the count of the number of instructors in that department. We can define the function as shown in Figure 1.
 Figure 1 Function defined in SQL
Figure 1 Function defined in SQL
This function can be used in a query that returns names and budgets of all departments with more than 12 instructors:![]() The SQL standard supports functions that can return tables as results; such functions are called table functions. Consider the function defined in Figure 2. The function returns a table containing all the instructors of a particular department. Note that the function’s parameter is referenced by prefixing it with the name of the function (instructor_of.dept_name). The function can be used in a query as follows:
The SQL standard supports functions that can return tables as results; such functions are called table functions. Consider the function defined in Figure 2. The function returns a table containing all the instructors of a particular department. Note that the function’s parameter is referenced by prefixing it with the name of the function (instructor_of.dept_name). The function can be used in a query as follows:![]() This query returns all instructors of the ‘Finance’ department. In the above simple case it is straightforward to write this query without using table-valued functions. In general, however, table-valued functions can be thought of as parameterized views that generalize the regular notion of views by allowing parameters.
This query returns all instructors of the ‘Finance’ department. In the above simple case it is straightforward to write this query without using table-valued functions. In general, however, table-valued functions can be thought of as parameterized views that generalize the regular notion of views by allowing parameters.
 Figure 2 Table function in SQL
Figure 2 Table function in SQL
SQL also supports procedures. The dept_count function could instead be written as a procedure: The keywords in and out indicate, respectively, parameters that are expected to have values assigned to them and parameters whose values are set in the procedure in order to return results. Procedures can be invoked either from an SQL procedure or from embedded SQL by the call statement:
The keywords in and out indicate, respectively, parameters that are expected to have values assigned to them and parameters whose values are set in the procedure in order to return results. Procedures can be invoked either from an SQL procedure or from embedded SQL by the call statement:![]() Procedures and functions can be invoked from dynamic SQL, as illustrated by the JDBC syntax in previous section.
Procedures and functions can be invoked from dynamic SQL, as illustrated by the JDBC syntax in previous section.
SQL permits more than one procedure of the same name, so long as the number of arguments of the procedures with the same name is different. The name, along with the number of arguments, is used to identify the procedure. SQL also permits more than one function with the same name, so long as the different functions with the same name either have different numbers of arguments, or for functions with the same number of arguments, they differ in the type of at least one argument.
1.2 Language Constructs for Procedures and Functions
SQL supports constructs that give it almost all the power of a general-purpose programming language. The part of the SQL standard that deals with these constructs is called the Persistent Storage Module (PSM). Variables are declared using a declare statement and can have any valid SQL data type. Assignments are performed using a set statement.
A compound statement is of the form begin . . . end, and it may contain multiple SQL statements between the begin and the end. Local variables can be declared within a compound statement, as we have seen in previous section. A compound statement of the form begin atomic . . . end ensures that all the statements contained within it are executed as a single transaction. SQL:1999 supports the while statements and the repeat statements by the following syntax: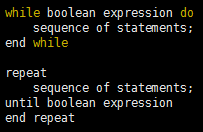 There is also a for loop that permits iteration over all results of a query:
There is also a for loop that permits iteration over all results of a query: The program fetches the query results one row at a time into the for loop variable (r, in the above example). The statement leave can be used to exit the loop, while iterate starts on the next tuple, from the beginning of the loop, skipping the remaining statements. The conditional statements supported by SQL include if-then-else statements by using this syntax:
The program fetches the query results one row at a time into the for loop variable (r, in the above example). The statement leave can be used to exit the loop, while iterate starts on the next tuple, from the beginning of the loop, skipping the remaining statements. The conditional statements supported by SQL include if-then-else statements by using this syntax: SQL also supports a case statement similar to the C/C++ language case statement. Figure 3 provides a larger example of the use of procedural constructs in SQL. The function registerStudent defined in the figure, registers a student in a course section, after verifying that the number of students in the section does not exceed the capacity of the room allocated to the section. The function returns an error code, with a value greater than or equal to 0 signifying success, and a negative value signifying an error condition, and a message indicating the reason for the failure is returned as an out parameter.
SQL also supports a case statement similar to the C/C++ language case statement. Figure 3 provides a larger example of the use of procedural constructs in SQL. The function registerStudent defined in the figure, registers a student in a course section, after verifying that the number of students in the section does not exceed the capacity of the room allocated to the section. The function returns an error code, with a value greater than or equal to 0 signifying success, and a negative value signifying an error condition, and a message indicating the reason for the failure is returned as an out parameter.
 Figure 3 Procedure to register a student for a course section
Figure 3 Procedure to register a student for a course section
The SQL procedural language also supports the signaling of exception conditions, and declaring of handlers that can handle the exception, as in this code: The statements between the begin and the end can raise an exception by executing signal out_of_classroom_seats. The handler says that if the condition arises, the action to be taken is to exit the enclosing begin end statement. Alternative actions would be continue, which continues execution from the next statement following the one that raised the exception. In addition to explicitly defined conditions, there are also predefined conditions such as sqlexception, sqlwarning, and not found.
The statements between the begin and the end can raise an exception by executing signal out_of_classroom_seats. The handler says that if the condition arises, the action to be taken is to exit the enclosing begin end statement. Alternative actions would be continue, which continues execution from the next statement following the one that raised the exception. In addition to explicitly defined conditions, there are also predefined conditions such as sqlexception, sqlwarning, and not found.
1.3 External Language Routines
Although the procedural extensions to SQL can be very useful, they are unfortunately not supported in a standard way across databases. Even the most basic features have different syntax or semantics in different database products. As a result, programmers have to essentially learn a new language for each database product. An alternative that is gaining in support is to define procedures in an imperative programming language, but allow them to be invoked from SQL queries and trigger definitions.
SQL allows us to define functions in a programming language such as Java, C#, C or C++. Functions defined in this fashion can be more efficient than functions defined in SQL, and computations that cannot be carried out in SQL can be executed by these functions. External procedures and functions can be specified in this way (note that the exact syntax depends on the specific database system you use): In general, the external language procedures need to deal with null values in parameters (both in and out) and return values. They also need to communicate failure / success status, to deal with exceptions. This information can be communicated by extra parameters: an sqlstate value to indicate failure / success status, a parameter to store the return value of the function, and indicator variables for each parameter / function result to indicate if the value is null. Other mechanisms are possible to handle null values, for example by passing pointers instead of values. The exact mechanisms depend on the database. However, if a function does not deal with these situations, an extra line parameter style general can be added to the declaration to indicate that the external procedure / functions take only the arguments shown and do not handle null values or exceptions.
In general, the external language procedures need to deal with null values in parameters (both in and out) and return values. They also need to communicate failure / success status, to deal with exceptions. This information can be communicated by extra parameters: an sqlstate value to indicate failure / success status, a parameter to store the return value of the function, and indicator variables for each parameter / function result to indicate if the value is null. Other mechanisms are possible to handle null values, for example by passing pointers instead of values. The exact mechanisms depend on the database. However, if a function does not deal with these situations, an extra line parameter style general can be added to the declaration to indicate that the external procedure / functions take only the arguments shown and do not handle null values or exceptions.
Functions defined in a programming language and compiled outside the database system may be loaded and executed with the database-system code. However, doing so carries the risk that a bug in the program can corrupt the database internal structures, and can bypass the access-control functionality of the database system. Database systems that are concerned more about efficient performance than about security may execute procedures in such a fashion. Database systems that are concerned about security may execute such code as part of a separate process, communicate the parameter values to it, and fetch results back, via interprocess communication. However, the time overhead of interprocess communication is quite high; on typical CPU architectures, tens to hundreds of thousands of instructions can execute in the time taken for one interprocess communication.
If the code is written in a “safe” language such as Java or C#, there is another possibility: executing the code in a sandbox within the database query execution process itself. The sandbox allows the Java or C# code to access its own memory area, but prevents the code from reading or updating the memory of the query execution process, or accessing files in the file system. (Creating a sandbox is not possible for a language such as C, which allows unrestricted access to memory through pointers.) Avoiding interprocess communication reduces function call overhead greatly.
Several database systems today support external language routines running in a sandbox within the query execution process. For example, Oracle and IBM DB2 allow Java functions to run as part of the database process. Microsoft SQL Server allows procedures compiled into the Common Language Runtime (CLR) to execute within the database process; such procedure could have been written, for example, in C# or Visual Basic. PostgreSQL allows functions defined in several languages, such as Perl, Python, and Tcl.
2 Triggers
A trigger is a statement that the system executes automatically as a side effect of a modification to the database. To design a trigger mechanism, we must meet two requirements:
- Specify when a trigger is to be executed. This is broken up into an event that causes the trigger to be checked and a condition that must be satisfied for trigger execution to proceed.
- Specify the actions to be taken when the trigger executes.
Once we enter a trigger into the database, the database system takes on the responsibility of executing it whenever the specified event occurs and the corresponding condition is satisfied.
2.1 Need for Triggers
Triggers can be used to implement certain integrity constraints that cannot be specified using the constraint mechanism of SQL. Triggers are also useful mechanisms for alerting humans or for starting certain tasks automatically when certain conditions are met. As an illustration, we could design a trigger that, whenever a tuple is inserted into the takes relation, updates the tuple in the student relation for the student taking the course by adding the number of credits for the course to the student’s total credits. As another example, suppose a warehouse wishes to maintain a minimum inventory of each item; when the inventory level of an items falls below the minimum level, an order can be placed automatically. On an update of the inventory level of an item, the trigger compares the current inventory level with the minimum inventory level for the item, and if the level is at or below the minimum, a new order is created.
Note that trigger systems cannot usually perform updates outside the database, and hence, in the inventory replenishment example, we cannot use a trigger to place an order in the external world. Instead, we add an order to a relation holding reorders. We must create a separate permanently running system process that periodically scans that relation and places orders. Some database systems provide built-in support for sending email from SQL queries and triggers, using the above approach.
2.2 Triggers in SQL
We now consider how to implement trigger in SQL. The syntax we present here is defined by the SQL standard, but most databases implement nonstandard versions of this syntax. Although the syntax we present here may not be supposed on such systems, the concepts we describe are applicable across implementations.
Figure 1 shows how triggers can be used to ensure referential integrity on the time_slot_id attribute of the section relation. The first trigger definition in the figure specifies that the trigger is initiated after any insert on the relation section and it ensures that the time_slot_id value being inserted is valid. An SQL insert statement could insert multiple tuples of the relation, and the for each row clause in the trigger code would then explicitly iterate over each inserted row. The referencing new row as clause creates a variable nrow (called a transition variable) that stores the value of an inserted row after the insertion.
 Figure 1 Using triggers to maintain referential integrity.
Figure 1 Using triggers to maintain referential integrity.
The when statement specifies a condition. The system executes the rest of the trigger body only for tuples that satisfy the condition. The begin atomic . . . end clause can serve to collect multiple SQL statements into a single compound statement. In our example, though, there is only one statement, which rolls back the transaction that caused the trigger to get executed. Thus any transaction that violates the referential integrity constraint gets rolled back, ensuring the data in the database satisfies the constraint.
It is not sufficient to check referential integrity on inserts alone, we also need to consider updates of section, as well as deletes and updates to the referenced table time_slot. The second trigger definition in Figure 1 considers the case of deletes to time_slot. This trigger checks that the time_slot_id of the tuple being deleted is either still present in time_slot, or that no tuple in section contains that particular time_slot_id value; otherwise, referential integrity would be violated.
To ensure referential integrity, we would also have to create triggers to handle updates to section and time_slot; we describe next how triggers can be executed on updates, but leave the definition of these triggers as an exercise to the reader. For updates, the trigger can specify attributes whose update causes the trigger to execute; updates to other attributes would not cause it to be executed. For example, to specify that a trigger executes after an update to the grade attribute of the takes relation, we write:![]() The referencing old row as clause can be used to create a variable storing the old value of an updated or deleted row. The referencing new row as clause can be used with tuples in addition to inserts. Figure 2 shows how a trigger can be used to keep the tot_cred attribute value of student tuples up_to_date when the grade attribute is updated for a tuple in takes relation. The trigger is executed only when the grade attributes is updated from a value that is either null or ‘F’, to a grade that indicates the course is successfully completed. The update statement is normal SQL syntax except for the use of the variable nrow.
The referencing old row as clause can be used to create a variable storing the old value of an updated or deleted row. The referencing new row as clause can be used with tuples in addition to inserts. Figure 2 shows how a trigger can be used to keep the tot_cred attribute value of student tuples up_to_date when the grade attribute is updated for a tuple in takes relation. The trigger is executed only when the grade attributes is updated from a value that is either null or ‘F’, to a grade that indicates the course is successfully completed. The update statement is normal SQL syntax except for the use of the variable nrow.
 Figure 2 Using a trigger to maintain credits_earned values
Figure 2 Using a trigger to maintain credits_earned values
A more realistic implementation of this example trigger would also handle grade corrections that change a successful completion grade to a fail grade, and handle insertions into the takes relation where the grade indicates successful completion. We leave these as an exercise for the reader. As another example of the use of a trigger, the action on delete of a student tuple could be to check if the student has any entries in the takes relation, and if so, to delete them.
Many database systems support a variety of other triggering events, such as when a user (application) logs on to the database (that is, opens a connection), the system shuts down, or changes are made to system settings. Triggers can be activated before the event (insert, delete, or update) instead of after the event. Triggers that execute before an event can serve as extra constraints that can prevent invalid updates, inserts, or deletes. Instead of letting the invalid action proceed and cause an error, the trigger might take action to correct the problem so that the update, insert, or delete becomes valid. For example, if we attempt to insert an instructor into a department whose name does not appear in the department relation, the trigger could insert a tuple into the department relation for that department name before the insertion generates a foreign-key violation. As another example, suppose the value of an inserted grade is blank, presumably to indicate the absence of a grade. We can define a trigger that replaces the value by the null value. The set statement can be used to carry out such modifications. An example of such a trigger appears in Figure 3.
 Figure 3 Example of using set to change an inserted value
Figure 3 Example of using set to change an inserted value
Instead of carrying out an action for each affected row, we can carry out a single action for the entire SQL statement that caused the insert, delete, or update. To do so, we use the for each statement clause instead of the for each row clause. The clauses referencing old table as or referencing new table as can then be used to refer to temporary tables (called transition tables) containing all the affected rows. Transition tables cannot be used with before triggers, but can be used with after triggers, regardless of whether they are statement triggers or row triggers. A single SQL statement can then be used to carry out multiple actions on the basis of the transition tables.
Triggers can be disabled or enabled; by default they are enabled when they are created, but can be disabled by using alter trigger trigger_name disable (some databases use alternative syntax such as disable trigger trigger_name). A trigger that has been disabled can be enabled again. A trigger can instead be dropped, which removes it permanently, by using the command drop trigger trigger_name.
Returning to our warehouse inventory example, suppose we have the following relations:
- inventory (item, level), which notes the current amount of the item in the warehouse.
- minlevel (item, level), which notes the minimum amount of the item to be maintained.
- reorder (item, amount), which notes the amount of the item to be ordered when its level falls below the minimum.
- orders (item, amount), which notes the amount of the item to be ordered.
Note that we have been careful to place an order only when the amount falls from above the minimum level to below the minimum level. If we check only that the new value after an update is below the minimum level. If we check only that the new value after an update is below the minimum level, we may place an order erroneously when the item has already been reordered. We can then use the trigger shown in Figure 4 for reordering the item. SQL-based database systems use triggers widely, although before SQL:1999 they were not part of the SQL standard. Unfortunately, each database system implemented its own syntax for triggers, leading to incompatibilities. The SQL:1999 syntax for triggers that we use here is similar, but not identical, to the syntax in the IBM DB2 and Oracle database systems.
2.3 When Not to Use Triggers
There are many good uses for triggers, such as those we have just seen in previous section, but some uses are best handled by alternative techniques. For example, we could implement the on delete cascade feature of a foreign-key constraint by using a trigger, instead of using the cascade feature. Not only would this be more work to implement, but also, it would be much harder for a database user to understand the set of constraints implemented in the database.
As another example, triggers can be used to maintain materialized views. For instance, if we wished to support very fast access to the total number of students registered for each course section, we could do this by creating a relation![]() defined by the query
defined by the query The value of total_students for each course must be maintained up-to-date by triggers on insert, delete, or update of the takes relation. Such maintenance may require insertion, update or deletion of tuples from section_registration, and triggers must be written accordingly. However, many database systems now support materialized views, which are automatically maintained by the database system. As a result, there is no need to write trigger code for maintaining such materialized views.
The value of total_students for each course must be maintained up-to-date by triggers on insert, delete, or update of the takes relation. Such maintenance may require insertion, update or deletion of tuples from section_registration, and triggers must be written accordingly. However, many database systems now support materialized views, which are automatically maintained by the database system. As a result, there is no need to write trigger code for maintaining such materialized views.
Triggers have been used for maintaining copies, or replicas, of databases. A collection of triggers on insert, delete, or update can be created on each relation to record the changes in relations called change or delta relations. A separate process copies over the changes to the replica of the database. Modern database systems, however, provide built-in facilities for database replication, making triggers unnecessary for replication in most cases. Replicated databases are discussed in detail in later series.
Another problem with triggers lies in unintended execution of the triggered action when data are loaded from a backup copy, or when database updates at a site are replicated on a backup site. In such cases, the triggered action has already been executed, and typically should not be executed again. When loading data, triggers can be disabled explicitly. For backup replica systems that may have to take over from the primary system, triggers would have to be disabled initially, and enabled when the backup site takes over processing from the primary system. As an alternative, some database systems allow triggers to be specified as not for replication, which ensures that they are not executed on the backup site during database replication. Other database systems provide a system variable that denotes that the database is a replica on which database actions are being replayed; the trigger body should check this variable and exit if it is true. Both solutions remove the need for explicit disabling and enabling of triggers.
Triggers should be written with great care, since a trigger error detected at runtime causes the failure of the action statement that set off the trigger. Furthermore, the action of one trigger can set off another trigger. In the worst case, this could even lead to an infinite chain of triggering. For example, suppose an insert trigger on a relation has an action that causes another (new) insert on the same relation. The insert action then triggers yet another insert action, and so on ad infinitum. Some database systems limit the length of such chains of triggers (for example, to 16 or 32) and consider longer chains of triggering an error. Other systems flag as an error any trigger that attempts to reference the relation whose modification caused the trigger to execute in the first place.
Triggers can serve a very useful purpose, but they are best avoided when alternatives exist. Many trigger applications can be substituted by appropriate use of stored procedures, which we discussed in previous section.