
Although the basic E-R concepts can model most database features, some aspects of a database may be more aptly expressed by certain extensions to the basic E-R model. In this section, we discuss the extended E-R features of specialization, generalization, higher-and lower-level entity sets, attribute inheritance, and aggregation.
To help with the discussions, we shall use a slightly more elaborate database schema for the university. In particular, we shall model the various people within a university by defining an entity set person, with attributes ID, name, and address.
1、Specialization
An entity set may include subgroupings of entities that are distinct in some way from other entities in the set. For instance, a subset of entities within an entity set may have attributes that are not shared by all the entities in the entity set. The E-R model provides a means for representing these distinctive entity groupings.
As an example, the entity set person may be further classified as one of the following:
- employee.
- student.
Each of these person types is described by a set of attributes that includes all the attributes of entity set person plus possibly additional attributes. For example, employee entities may be described further by the attribute salary, whereas student entities may be described further by the attribute tot_cred. The process of designating subgroupings within an entity set is called specialization. The specialization of person allows us to distinguish among person entities according to whether they correspond to employees or students: in general, a person could be an employee, a student, both, or neither.
As another example, suppose the university divides students into two categories: graduate and undergraduate. Graduate students have an office assigned to them. Undergraduate students are assigned to a residential college. Each of these student types is described by a set of attributes that includes all the attributes of the entity set student plus additional attributes. The university could create two specializations of student, namely graduate and undergraduate. As we saw earlier, student entities are described by the attributes ID, name, address, and tot_cred. The entity set graduate would have all the attributes of student and an additional attribute office_number. The entity set undergraduate would have all the attributes of student, and an additional attribute residential_college. We can apply specialization repeatedly to refine a design. For instance, university employees may be further classified as one of the following;
- instructor.
- secretary.
Each of these employee types is described by a set of attributes that includes all the attributes of entity set employee plus additional attributes. For example, instructor entities may be described further by the attribute rank while secretary entities are described by the attribute hours_per_week. Further, secretary entities may participate in a relationship secretary_for between the secretary and employee entity sets, which identifies the employees who are assisted by a secretary.
An entity set may be specialized by more than one distinguishing feature. In our example, the distinguishing feature among employee entities is the job the employee performs. Another, coexistent, specialization could be based on whether the person is a temporary (limited_term) employee or a permanent employee, resulting in the entity sets temporary_employee and permanent_employee. When more than one specialization is formed on an entity set, a particular entity may belong to multiple specializations. For instance, a given employee may be a temporary employee who is a secretary.
In terms of an E-R diagram, specialization is depicted by a hollow arrow-head pointing from the specialized entity to the other entity (see Figure 1). We refer to this relationship as the ISA relationship, which stands for “is a” and represents, for example, that an instructor “is a ”employee.
 Figure 1 Specialization and generalization.
Figure 1 Specialization and generalization.
The way we depict specialization in an E-R diagram depends on whether an entity may belong to multiple specialized entity sets or if it must belong to at most one specialized entity set. The former case (multiple sets permitted) is called overlapping specialization, while the latter case (at most one permitted) is called disjoint specialization. For an overlapping specialization (as is the case for student and employee as specializations of person), two separate arrows are used. For a disjoint specialization (as is the case for instructor and secretary as specializations of employee), a single arrow is used. The specialization relationship may also be referred to as a superclass-subclass relationship. Higher-and lower-level entity sets are depicted as regular entity sets——that is, as rectangles containing the name of the entity set.
2、Generalization
The refinement from an initial entity set into successive levels of entity subgroupings represents a top-down design process in which distinctions are made explicit. The design process may also proceed in a bottom-up manner, in which multiple entity sets are synthesized into a higher-level entity set on the basis of common features. The database designer may have first identified:
- instructor entity set with attributes instructor_id, instructor_name, instructor_salary, and rank.
- secretary entity set with attributes secretary_id, secretary_name, secretary_salary, and hours_per_week.
There are similarities between the instructor entity set and the secretary entity set in the sense that they have several attributes that are conceptually the same across the two entity sets: namely, the identifier, name, and salary attributes. This commonality can be expressed by generalization, which is a containment relationship that exists between a higher-level entity set and one or more lower-level entity sets. In our example, employee is the higher-level entity set and instructor and secretary are lower-level entity sets. In this case, attributes that are conceptually the same had different names in the two lower-level entity sets. To create a generalization, the attributes must be given a common name and represented with the higher-level entity person. We can use the attribute names ID, name, address, as we saw in the example in Section 1.
Higher- and lower-level entity sets also may be designated by the terms superclass and subclass, respectively. For all practical purposes, generalization is a simple inversion of specialization. We apply both process, in combination, in the course of designing the E-R schema for an enterprise. In terms of the E-R diagram itself, we do not distinguish between specialization and generalization. New levels of entity representation are distinguished (specialization) or synthesized (generalization) as the design schema comes to express fully the database application and the user requirements of the database. Differences in the two approaches may be characterized by their starting point and overall goal.
Specialization stems from a single entity set; it emphasizes differences among entities within the set by creating distinct lower-level entity sets. These lower-level entity sets may have attributes, or may participate in relationships, that do not apply to all the entities in the higher-level entity set. Indeed, the reason a designer applies specialization is to represent such distinctive features. If student and employee have exactly the same attributes as person entities, and participate in exactly the same relationships as person entities, there would be no need to specialize the person entity set.
Generalization proceeds from the recognition that a number of entity sets share some common features (namely, they are described by the same attributes and participate in the same relationship sets). On the basis of their commonalities, generalization synthesizes these entity sets into a single, higher-level entity set. Generalization is used to emphasize the similarities among lower-level entity sets and to hide the differences; it also permits an economy of representation in that shared attributes are not repeated.
3、Attribute Inheritance
A crucial property of the higher- and lower-level entities created by specialization and generalization is attribute inheritance. The attributes of the higher-level entity sets are said to be inherited by the lower-level entity sets. For example, student and employee inherit the attributes of person. Thus, student is described by its ID, name, and address attributes, and additionally a tot_cred attribute; employee is described by its ID, name, and address attributes, and additionally a salary attribute. Attribute inheritance applies through all tiers of lower-level entity sets; thus, instructor and secretary, which are subclasses of employee, inherit the attributes ID, name, and address from person, in addition to inheriting salary from employee.
A lower-level entity set (or subclass) also inherits participation in the relationship sets in which its higher-level entity (or superclass) participates. Like attribute inheritance, participation inheritance applies through all tiers of lower-level entity sets. For example, suppose the person entity set participates in a relationship person_dept with department. Then, the student, employee, instructor and secretary entity sets, which are subclasses of the person entity set, also implicitly participate in the person_dept relationship with department. The above entity sets can participate in any relationships in which the person entity set participates.
Whether a given portion of an E-R model was arrived at by specialization or generalization, the outcome is basically the same:
- A higher-level entity set with attributes and relationships that apply to all of its lower-level entity sets.
- Lower-level entity sets with distinctive features that apply only within a particular lower-level entity set.
In what follows, although we often refer to only generalization, the properties that we discuss belong fully to both processes. Figure 1 depicts a hierarchy of entity sets. In the figure, employee is a lower-level entity set of person and a higher-level entity set of the instructor and secretary entity sets. In a hierarchy, a given entity set may be involved as a lower-level entity set in only one ISA relationship; that is, entity sets in this diagram have only single inheritance. If an entity set is a lower-level entity set in more than one ISA relationship, then the entity set has multiple inheritance, and the resulting structure is said to be a lattice.
4、Constraints on Generalizations
To model an enterprise more accurately, the database designer may choose to place certain constraints on a particular generalization. One type of constraint involves determining which entities can be members of a given lower-level entity set. Such membership may be one of the following:
- Condition-defined. In condition-defined lower-level entity sets, membership is evaluated on the basis of whether or not an entity satisfies an explicit condition or predicate. For example, assume that the higher-level entity set student has the attribute student_type. All student entities are evaluated on the defining student_type attribute. Only those entities that satisfy the condition student_type = “graduate” are allowed to belong to the lower-level entity set graduate_student. All entities that satisfy the condition student_type = “undergraduate” are included in undergraduate_student. Since all the lower-level entities are evaluated on the basis of the same attribute (in this case, on student_type), this type of generalization is said to be attribute-defined.
- User-defined. User-defined lower-level entity sets are not constrained by a membership condition; rather, the database user assigns entities to a given entity set. For instance, let us assume that, after 3 months of employment, university employees are assigned to one of four work teams. We therefore represent the teams as four lower-level entity sets of the higher-level employee entity set. A given employee is not assigned to a specific team entity automatically on the basis of an explicit defining condition. Instead, the user in charge of this decision makes the team assignment on an individual basis. The assignment is implemented by an operation that adds an entity to an entity set.
A second type of constraint relates to whether or not entities may belong to more than one lower-level entity set within a single generalization. The lower-level entity sets may be one of the following:
- Disjoint. A disjointness constraint requires that an entity belong to no more than one lower-level entity set. In our example, student entity can satisfy only one condition fort the student_type attribute; an entity can be either a graduate student or an undergraduate student, but cannot be both.
- Overlapping. In overlapping generalizations, the same entity may belong to more than one lower-level entity set within a single generalization. For an illustration, consider the employee work-team example, and assume that certain employees participate in more than one work team. A given employee may therefore appear in more than one of the team entity sets that are lower-level entity sets of employee. Thus, the generalization is overlapping.
In Figure 1, we assume a person may be both an employee and a student. We show this overlapping generalization via separate arrows: one from employee to person and another from student to person. However, the generalization of instructor and secretaries is disjoint. We show this using a single arrow.
A final constraint, the completeness constraint on a generalization or specialization, specifies whether or not an entity in the higher-level entity set must belong to at least one of the lower-level entity sets within the generalization / specialization. This constraint may be one of the following:
- Total generalization or specialization. Each higher-level entity must belong to a lower-level entity set.
- Partial generalization or specialization. Some higher-level entities may not belong to any lower-level entity set.
Partial generalization is the default. We can specify total generalization in an E-R diagram by adding the keyword “total” in the diagram and drawing a dashed line from the keyword to the corresponding hollow arrow-head to which it applies (for a total generalization), or to the set of hollow arrow-heads to which it applies (for an overlapping generalization).
The student generalization is total: All student entities must be either graduate or undergraduate. Because the higher-level entity set arrived at through generalization is generally composed of only those entities in the lower-level entity sets, the completeness constraint for a generalized higher-level entity set is usually total. When the generalization is partial, a higher-level entity is not constrained to appear in a lower-level entity set. The work team entity sets illustrate a partial specialization. Since employees are assigned to a team only after 3 months on the job, some employee entities may not be members of any of the lower-level team entity sets.
We may characterize the team entity sets more fully as a partial, overlapping specialization of employee. The generalization of graduate_student and undergraduate_student into student is a total, disjoint generalization. The completeness and disjointness constraints, however, do not depend on each other. Constraint patterns may also be partial-disjoint and total-overlapping.
We can see that certain insertion and deletion requirements follow from the constraints that apply to a given generalization or specialization. For instance, when a total completeness constraint is in place, an entity inserted into a higher-level entity set must also be inserted into at least one of the lower-level entity sets. With a condition-defined constraint, all higher-level entities that satisfy the condition must be inserted into that lower-level entity set. Finally, an entity that is deleted from a higher-level entity set also is deleted from all the associated lower-level entity sets to which it belongs.
5、Aggregation
One limitation of the E-R model is that it cannot express relationships among relationships. To illustrate the need for such a construct, consider the ternary relationship proj_guide, which we saw earlier, between an instructor, student and project (see Figure 7 in Database Design ~ Database Design and the E-R Model II).
Now suppose that each instructor guiding a student on a project is required to file a monthly evaluation report. We model the evaluation report as an entity evaluation, with a primary key evaluation_id. One alternative for recording the (student, project, instructor) combination to which an evaluation corresponds is to create a quaternary (4-way) relationship set eval_for between instructor, student, project, and evaluation. (A quaternary relationship is required —— a binary relationship between student and evaluation, for example, would not permit us to represent the (project, instructor) combination to which an evaluation corresponds.) Using the basic E-R modeling constructs, we obtain the E-R diagram of Figure 2. (We have omitted the attributes of the entity sets, for simplicity.)
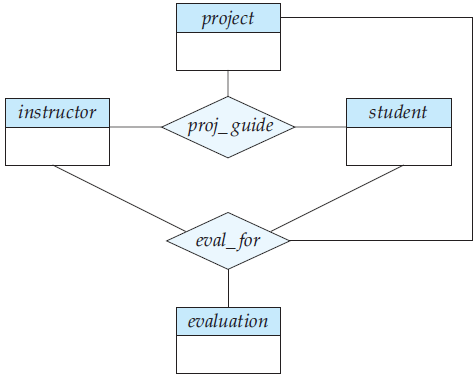 Figure 2 E-R diagram with redundant relationships.
Figure 2 E-R diagram with redundant relationships.
It appears that the relationship sets proj_guide and eval_for can be combined into one single relationship set. Nevertheless, we should not combine them into a single relationship, since some instructor, student, project combinations may not have an associated evaluation.
There is redundant information in the resultant figure, however, since every instructor, student, project combination in eval_for must also be in proj_guide. If the evaluation were a value rather than a entity, we could instead make evaluation a multivalued composite attribute of the relationship set proj_guide. However, this alternative may not be an option if an evaluation may also be related to other entities; for example, each evaluation report may be associated with a secretary who is responsible for further processing of the evaluation report to make scholarship payments.
The best way to model a situation such as the one just described is to use aggregation. Aggregation is an abstraction through which relationships are treated as higher-level entities. Thus, for our example, we regard the relationship set proj_guide (relating the entity sets instructor, student, and project) as a higher-level entity set called proj_guide. Such an entity set is treated in the same manner as is any other entity set. We can then create a binary relationship eval_for between proj_guide and evaluation to represent which (student, project, instructor) combination an evaluation is for. Figure 3 shows a notation for aggregation commonly used to represent this situation.
 Figure 3 E-R diagram with aggregation.
Figure 3 E-R diagram with aggregation.
6、Reduction to Relation Schemas
We are in a position now to describe how the extended E-R features can be translated into relation schemas.
6.1 Representation of Generalization
There are two different methods of designing relation schemas for an E-R diagram that includes generalization. Although we refer to the generalization in Figure 1 in this discussion, we simplify it by including only the first tier of lower-level entity sets——that is, employee and student. We assume that ID is the primary key of person.
- Create a schema for the higher-level entity set. For each lower-level entity set, create a schema that includes an attribute for each of the attributes of that entity set plus one for each attribute of the primary key of the higher-level entity set. Thus, for the E-R diagram of Figure 1 (ignoring the instructor and secretary entity sets) we have three schemas:
 The primary-key attributes of the higher-level entity set become primary-key attributes of the higher-level entity set as well as all lower-level entity sets. These can be seen underlined in the above example. In addition, we create foreign-key constraints on the lower-level entity sets, with their primary-key attributes referencing the primary key of the relation created from the higher-level entity set. In the above example, the ID attribute of employee would reference the primary key of person, and similarly for student.
The primary-key attributes of the higher-level entity set become primary-key attributes of the higher-level entity set as well as all lower-level entity sets. These can be seen underlined in the above example. In addition, we create foreign-key constraints on the lower-level entity sets, with their primary-key attributes referencing the primary key of the relation created from the higher-level entity set. In the above example, the ID attribute of employee would reference the primary key of person, and similarly for student. - An alternative representation is possible, if the generalization is disjoint and complete——that is, if no entity is a number of two lower-level entity sets directly below a higher-level entity set, and if every entity in the higher-level entity set is also a member of one of the lower-level entity sets. Here, we do not create a schema for the higher-level entity set. Instead, for each lower-level entity set, we create a schema that includes an attribute for each of the attributes of that entity set plus one for each attribute of the higher-level entity set. Then, for the E-R diagram of Figure 1, we have two schemas:
 Both these schemas have ID, which is the primary-key attribute of the higher-level entity set person, as their primary key.
Both these schemas have ID, which is the primary-key attribute of the higher-level entity set person, as their primary key.
One drawback of the second method lies in defining foreign-key constraints. To illustrate the problem, suppose we had a relationship set R involving entity set person. With the first method, when we create a relation schema R from the relationship set, we would also define a foreign-key constraint on R, referencing the schema person. Unfortunately, with the second method, we do not have a single relation to which a foreign-key constraint on R can refer. To avoid this problem, we need to create a relation schema person containing at least the primary-key attributes of the person entity.
If the second method were used for an overlapping generalization, some values would be stored multiple times, unnecessarily. For instance, if a person is both an employee and a student, values for street and city would be stored twice. If the generalization were disjoint but complete——that is, if some person is neither an employee nor a student——then an extra schema![]() would be required to represent such people. However, the problem with foreign-key constraints mentioned above would remain. As an attempt to work around the problem, suppose employees and students are additionally represented in the person relation. Unfortunately, name, street, and city information would then be stored redundantly in the person relation and the student relation for the students, and similarly in the person relation and the employee relation for employees. That suggests storing name, street, and city information only in the person relation and removing that information from student and employee. If we do that, the result is exactly the first method we presented.
would be required to represent such people. However, the problem with foreign-key constraints mentioned above would remain. As an attempt to work around the problem, suppose employees and students are additionally represented in the person relation. Unfortunately, name, street, and city information would then be stored redundantly in the person relation and the student relation for the students, and similarly in the person relation and the employee relation for employees. That suggests storing name, street, and city information only in the person relation and removing that information from student and employee. If we do that, the result is exactly the first method we presented.
6.2 Representation of Aggregation
Designing schemas for an E-R diagram containing aggregation is straightforward. Consider the diagram of Figure 3. The schema for the relationship set eval_for between the aggregation of proj_guide and the entity set evaluation includes an attribute for each attribute in the primary keys of the entity set evaluation, and the relationship set proj_guide. It also includes an attribute for any descriptive attributes, if they exist, of the relationship set eval_for. We then transform the relationship sets and entity sets within the aggregated entity set following the rules we have already defined.
The rules we saw earlier for creating primary-key and foreign-key constraints on relationship sets can be applied to relationship sets involving aggregations as well, with the aggregation treated like any other entity set. The primary key of the aggregation is the primary key of its defining relationship set. No separate relation is required to represent the aggregation; the relation created from the defining relationship is used instead.